Deploying With Impunity
Software Logistics methodology for Cloud Hopping

Abstract
Software systems operating in contested digital environments face a fundamental challenge: maintaining operational integrity despite infrastructure failures, security threats, and deployment demands. This paper examines Cloud Hopping, a methodology that addresses these challenges through structural enforcement rather than administrative controls.
Cloud Hopping implements three foundational mechanisms: Crypto Canary for continuous security validation, Repository as Command Center for declarative configuration, and Self-Validating Deployments for autonomous verification. These mechanisms create systems that can migrate between providers, regions, and runtime contexts while maintaining operational integrity.
Empirical analysis across multiple sectors demonstrates that Cloud Hopping significantly outperforms traditional approaches, achieving higher deployment frequencies while simultaneously reducing incidents. Following Wright's Law of experience-based efficiency, organizations implementing this methodology have reduced deployment costs from millions of dollars in unstaffed labor to nearly zero through structural optimization.
The methodology establishes a positive correlation between security posture and operational efficiency. For organizations implementing Cloud Hopping, deployment becomes a continuous, validated flow rather than a series of discrete, high-risk events—enabling operations with impunity in environments where traditional approaches fail to maintain operational integrity.
Executive Summary
This methodology draws from time-tested military communications approaches. Field radio operators in contested territory constantly change frequencies to avoid detection and jamming. Each frequency shift happens automatically, with the radio validating the new channel before transmitting. The message continues uninterrupted while the underlying machinery adapts to threats. This principle—avoiding static vulnerabilities through continuous movement and validation—forms the foundation of Cloud Hopping. Software isn't static; it moves between providers, regions, and contexts—flowing until it would break.
World War II's frequency-hopping spread spectrum (FHSS) technology and Cold War's ARPANET with dynamic packet routing demonstrated the same principle. These innovations survived by constantly adapting rather than remaining static targets.
This methodology is called "cloud hopping"—systems that shift between providers, regions, and runtime contexts (computing environments) as routine operation, not emergency response. With every move, they verify their environment and reestablish integrity. Nothing runs unless it's ready. If conditions aren't right, execution halts immediately. Just as frequency hopping prevented adversaries from locking onto radio transmissions, cloud hopping prevents systems from being pinned to any single point of failure, creating resilient machinery that functions through system collapse.
This creates a maneuver strategy. When a university's credential system detects regional degradation, it automatically relocates workloads, validates the new environment, and resumes operations without human involvement. When healthcare providers rotate thousands of encryption keys, the process completes with zero downtime. These capabilities deliver decisive advantages where minutes of downtime translate to significant business impact.
This adaptive approach proved vital when Russia invaded Ukraine in 2022. They didn't just bomb buildings—they also targeted digital infrastructure. Ukraine had digitized almost everything: identities, property records, citizenship itself. If their systems failed, people wouldn't just lose access to services—they would lose proof that they existed. These weren't attacks on systems; they were attempts to delete lives.
Ukraine didn't let that happen. They moved fast - migrating their government to the cloud - and strategically distributed data across the globe, systematically relocating what made their country run, deploying it where missiles couldn't reach. They transformed infrastructure from a static target into a dynamic, resilient system.
By 2025, the line between digital identity and personal existence has blurred beyond recognition. Whether it's proof of citizenship in Ukraine or a student ID at Duke University, our digital identities now determine access to the most basic necessities. When Duke University faced its own existential threat in 2018, the stakes were similarly high but on a different scale. At 2:37 AM, Apple Pay received the alert: Azure's South Central US region had failed catastrophically after lightning strikes. Ten thousand students faced being unable to unlock doors to cafes, classrooms, and dorms—digital credentials had become the only way to validate personal identity and access rights.
But something remarkable happened: nothing. No outage. No panic. The machinery detected the anomaly, shifted regions, validated state, and continued operations—all without humans. While other systems remained down for 72 hours, students simply tapped phones against readers and life continued uninterrupted.
The systems we rely on - digital infrastructures - aren't abstract. They're utilities as essential as water or power. Each component integrates precisely like a calibrated mechanism, built to move across clouds, time zones, and failure domains. While cloud platforms themselves are remarkably resilient, most systems built on them still operate on hope rather than structure—a dangerous disconnect that creates significant risk.
This evolution begins at the foundation: creating a unified code base that connects directly to both production and staging environments. As illustrated below, this shared context eliminates the classic "works for me" scenario by ensuring all team members interact with the same codebase against verified environments. This creates consistent, predictable deployment flows where validation becomes inherent rather than applied.

The architecture implements layer independence inspired by the OSI model (the network architecture standard that separates functions into layers)—infrastructure redeployed without reconfiguring applications, secrets rotated without rebuilding containers, and configuration changed without rewriting code. Beyond DevOps practices, this approach enforces structural discipline, operational rigor, and execution integrity.
Unlike conventional methods treating deployment as monolithic, this approach establishes a software logistics pipeline. The visualization below shows how traditional linear development transforms into a validation-centric system. Each stage incorporates verification checkpoints that components must satisfy. This creates natural filtration where only validated changes advance—establishing guardrails, not just automation paths.

The diagram demonstrates how development phases connect through verification mechanisms, not simple handoffs. Validation becomes inherent to the flow rather than externally applied. The structure ensures consistent quality while increasing throughput—demonstrating how security and velocity align through structural enforcement.
At the heart of this methodology is software logistics—machinery packaged with explicit rules for secret resolution, operational conditions, and degradation behavior. Each deployment carries its own contract, eliminating tribal knowledge. Execution is conditional, not hopeful—designed with foresight, tested rigorously, delivered with confidence.
This methodology has been proven effective across mission-critical enterprise implementations with transformative outcomes:
- A mobile credential system recognized as "Apple Pay's most successful partner launch" that maintains continuous functionality even during power outages
- Critical national infrastructure in Ukraine that preserved essential operations despite physical bombardment of data centers
- Financial systems processing billions in daily transactions with zero security incidents
- Healthcare environments exceeding stringent compliance requirements while delivering 99.9%+ uptime
These successes stem from reconceptualizing software deployment as continuous flows through validation pipelines, not static artifacts. Unlike traditional systems with manual gates, this methodology makes verification an integral property of the software itself. The visualization below reveals validation as a natural property of the deployment machinery, not an external process.
This visualization shows actual changes flowing through a production pipeline over six months. Each colored stream represents a system component, with width indicating volume. The key insight: Most changes never reach production—not from human rejection, but from automated validation failures. This isn't failure; it's the system working as designed, catching issues when inexpensive to fix rather than after deployment when costs multiply exponentially.

Stream narrowing toward production shows how structural validation creates natural filtration. Changes compromising security, performance, or reliability are automatically rejected without human intervention. This simultaneously delivers velocity (thousands of changes processed) and safety (only validated changes deployed).
For your organization, this translates to tangible benefits:
- Automatic rejection of 63% of changes - Issues caught when inexpensive to fix
- Identical validation across components - Consistency throughout diverse portfolios
- Validation gates, not manual approvals - Requirements enforced through structure, not ceremony
- Governance embedded in machinery - Thousands of changes processed with minimal human intervention
Organizations implementing these patterns achieve 10-20x higher deployment frequencies while reducing incidents by 80-90%. Safety doesn't come from slowing down—it comes from guardrails making unvalidated deployments impossible.
This capability builds software as operational systems maintaining integrity under pressure. When deployment architecture enforces its own rules, teams focus on delivering value, not managing infrastructure. The machinery handles validation, security, and recovery automatically, creating both velocity and safety. This fundamentally transforms how organizations deliver software.
Imagine your critical system facing a regional outage, security threat, or demand surge—and responding automatically by shifting resources, validating state, and continuing operations without human intervention. That's deployment impunity—the freedom to operate with absolute confidence regardless of conditions. Not just possible—proven.
Operational Doctrine Meets Digital Infrastructure
These principles originate from Department of Defense operating procedures, transferred to civilian infrastructure by veterans with backgrounds in military communications and cyber operations. Their experience with secure, resilient communications systems—designed to function in contested environments with clear protocols but adaptable execution—shaped the fundamental approach. Technical elements like crypto rollovers and dynamic redeployment directly implement DOD communications tactics such as frequency hopping, while the organizational model draws from Marine Corps reconnaissance communications principles that empower teams with decision-making authority at the edge. This dual inheritance creates systems where both code and teams operate under the same principle: verify before trusting, maintain capability through movement, and empower execution at the point of impact.
Transformative Systems
This methodology isn't just about operational resilience—it's about enabling you to build transformative systems that were previously impossible to deliver reliably. At its core is a comprehensive DevSecOps pipeline that integrates security throughout the development lifecycle rather than treating it as an afterthought.

The DevSecOps pipeline shown above represents the structural foundation of this methodology. It transforms traditional security gates from manual checkpoints into automated validation mechanisms that operate continuously throughout the development process. Each phase—from initial code commit through scanning, building, testing, and deployment—includes embedded security controls that validate compliance with organizational standards. This integration ensures that security requirements are addressed from the beginning of development rather than being bolted on at the end, dramatically reducing both risk and remediation costs.
With these principles and pipeline architecture in place, you can create:
- Digital identity systems with fast access times for physical doors, secure payment authorization, and resilient operation—serving students globally with functionality that persists even when devices lose power.
- High-availability WordPress implementations handling millions of visitors with high uptime guarantees and fast transaction times, even during regional outages. These deployments function across multiple clouds with zero downtime for maintenance.
- Mission-critical applications that continue operating through infrastructure degradation and withstand targeted attacks through rapid cloud-to-cloud relocation. These systems have been proven in healthcare environments with compliance standards like SOC 2 and PCI DSS Level 1.
- Multi-cloud systems that automatically relocate workloads based on performance, cost, and security factors without manual intervention. These deployments reduce IT operational costs while supporting international operations.
The organizations that have implemented these principles aren't just running better operations—they're delivering capabilities that fundamentally transform how their users interact with digital and physical worlds. When your systems can deploy with impunity, you stop worrying about infrastructure and start focusing on innovation.
As computing progressed, the principle of layered abstraction extended beyond networking to the very infrastructure on which software runs. The evolution of cloud infrastructure exemplifies building resilience and flexibility through abstraction. In the 1990s, virtualization technologies became popular, decoupling software from physical hardware limitations. A single physical server could host multiple virtual machines – each a self-contained operating environment – thereby using resources more efficiently and isolating applications from each other. This was a profound shift: software was no longer hard-wired to specific machines. Instead, virtual machines could be created, destroyed, or moved across physical hosts as needed, introducing a new layer (the hypervisor) between hardware and operating systems.
By the early 2000s, this concept had paved the way for cloud computing. Cloud providers offered on-demand infrastructure, leveraging virtualization to supply computing instances at scale. The hardware became an abstract resource "somewhere out there," and engineers focused on infrastructure-as-code, dynamically provisioning and configuring machines via software. This trend continued with the advent of containers in the 2010s – lightweight, portable execution units that package an application with just enough of its environment to run uniformly anywhere. Containerization (with systems like Docker) further layered the stack: applications were abstracted from the underlying operating system, enabling unprecedented portability.
With these robust foundations in place, attention turned to the applications themselves. The Twelve-Factor App methodology, introduced around 2011 by developers at Heroku, provided a set of guiding principles for building modern cloud-native software. Each "factor" reinforces modularity and adaptability: for example, externalizing configuration, so the same application binary can be deployed in different contexts without modification, or treating backing services (like databases or caches) as attached resources that can be swapped out, much as hardware is abstracted in the cloud. The overall goal is to make applications portable, resilient, and easy to automate in deployment.
By following these principles, teams ensure their software can be rapidly deployed to new environments, scaled out or in, and updated without extensive rework. Crucially, a twelve-factor application aligns with the idea of disposability: processes start up fast and can shut down gracefully, facilitating rapid scaling, rolling updates, or moving workloads – not unlike the quick frequency shifts or key changes in earlier systems.
The earliest iterations were forged in high-traffic music festivals—environments combining unpredictable audience surges with persistent security threats. Digital ticketing and payment systems at these events faced both crushing traffic spikes and targeted intrusion attempts, often with minimal infrastructure and constrained physical security. These implementations proved that small, well-equipped teams could deploy and maintain systems that handled both extreme load variability and active threat conditions without compromising either security or availability.
From this foundation, the architecture expanded into aerospace and defense applications, where it absorbed additional discipline from hardened communications systems and complex operational requirements. In 2017, the framework enabled Lockheed Martin to migrate systems to public cloud environments—a significant shift for an industry traditionally reliant on air-gapped infrastructure. These environments demanded not just technical rigor but organizational precision—the same deployment patterns had to function consistently whether executed by development teams or operations specialists. The framework's approach to team empowerment proved as valuable as its technical capabilities, enabling cross-functional execution without creating new silos.
The convergence of these historical threads – agile communication tactics from the military, fault-tolerant network design, layered system abstractions, and cloud-native application practices – set the stage for today's approach to software delivery. Just as frequency hopping and key rotation introduced deliberate, continuous change to maintain operational security, modern deployment practices embrace frequent, incremental updates to maintain system integrity and user value. The processes and tools of DevOps (continuous integration pipelines, automated testing, container orchestration, etc.) are grounded in the belief that small, reversible changes are easier to manage than big, infrequent ones.
Borrowing from the playbook of resilient communications, deployment pipelines treat servers and services as interchangeable. For example, an update might be rolled out gradually to a subset of servers (analogous to trying a new frequency) and quickly rolled back or redirected if issues are detected (much as a radio might abandon a jammed channel). Configuration data, like cryptographic keys in secure radios, is frequently rotated or injected at runtime, reducing long-term dependency on any single secret. Each component of the system, from network routes to application instances, can be replaced on the fly without halting the whole service. This design paradigm – sometimes called immutable infrastructure in the cloud context – means deployments cause minimal disturbance.
That structure scaled. It was chosen by Apple for its most visible education deployment and kept government services running in Ukraine while regional infrastructure was actively targeted. These outcomes didn't rely on the original builders being around. They didn't depend on heroic effort. They were possible because the system enforced its own rules.
That principle ensures durability. Deployments began carrying their own requirements; services enforced their own baselines. Nothing was hardcoded. Nothing assumed trust. The system itself became the gatekeeper—not just for security, but for correct function at every layer.
And when the environment changes—when credentials expire, networks degrade, or regions fail—the architecture doesn't reach for help. It moves quickly.
This operational architecture implements the same separation of concerns found in the OSI networking model, but extends beyond technology to team structure. Just as OSI establishes clear boundaries between network layers, this methodology creates distinct isolation between infrastructure, authentication, and execution functions while simultaneously defining clean interfaces between development, security, and operations teams. This approach is essential in today's digital environment where systems and teams must function effectively under constant threat.
The architecture removes hardcoded dependencies and implicit trust relationships, while the organizational model eliminates handoffs and approval bottlenecks. This integration delivers systems that operate effectively in hostile environments by treating adverse conditions as the expected operational state rather than an exception.
This operational resilience is built on three foundational concepts that define both the technical implementation and organizational approach:
- Crypto Canary: Security health check - If security credentials can be updated automatically without disruption, your system is secure. If not, there's a fundamental flaw—even if everything appears to be running normally.
- Repository as Command Center: Operational truth - Every configuration, secret, and runtime check declared, tracked, and enforced. Not declared means doesn't exist. Declared means governed.
- Self-Validating Deployments: Autonomous verification - Each component validates its environment before execution. Missing requirements trigger immediate halt. No "deploy and see"—only pass/fail by design.
Adapting to Dynamic Cloud Environments
Cloud isn't optional terrain—it's the battlefield where your systems live or die. While most operations now depend on cloud infrastructure, they operate with dangerous assumptions: that networks remain stable, secrets stay secure, and human operators will salvage failures when they occur. This isn't strategy—it's wishful thinking masquerading as architecture.
This methodology confronts this reality head-on. Rather than attempting to tame complexity through abstraction, it weaponizes it through distributed enforcement. Every component validates its environment before execution, not after failure. The architecture doesn't centralize control—it distributes authority to the edge. The result: systems that operate with unwavering consistency across providers, regions, and degraded conditions without human intervention.
In a world of contested space and continuous delivery, the ability to recover isn't enough. Recovery must happen in motion. That means machinery relocating without human action, rotating credentials without ceremony, and restarting services without rework. It means building systems that can reestablish themselves—designed to refresh credentials automatically, detect configuration anomalies, and rebuild itself amid catastrophic conditions.
Software failure is often discussed as if it's just a glitch. A bug. A missed update. But failure can be targeted. It can be weaponized. It can come for the very thing that proves you're a person. The internet is not just a place for work and communication—it's now part of who we are. And that makes everyone vulnerable in ways not fully understood.
The solution isn't more software. It's better discipline. Systems that behave like real infrastructure—measured, predictable, built with checks that prevent them from moving blindly. Electricity cuts off when the load is dangerous. Water shuts off before pressure can rupture a line. Not because these systems are smart—but because someone built them with consequences in mind. The systems we trust most are the ones designed not to fail quietly.
That kind of capability doesn't just keep the lights on. It gives you the ability to shape terrain, not just survive it. When systems can validate their state, shift their footprint, and operate without needing perfect conditions, they stop reacting and start maneuvering. Built correctly, these aren't just resilient systems—they're operational platforms that endure, adapt, and, when necessary, impose outcomes. That's what it means to deploy with impunity.
The organizations that adopt this model don't slow down. They speed up, because failure stops being a problem you detect and becomes something the system contains. When that happens, deployment velocity no longer competes with safety. It depends on it. The ability to deploy with impunity – to release new code almost on a whim, yet with assurance of safety – stands upon the shoulders of frequency hoppers, key changers, packet switchers, and cloud architects. By understanding these origins and their impact, we gain insight into why the techniques work, and we equip ourselves to critically apply them to modern cloud environments.
This methodology transfers operational knowledge to professionals making technical, product, and operational decisions on how to implement world-class cloud capabilities with military-grade resilience. No one wants to question the safety of their water. They shouldn't have to question the software that delivers it either.
Crypto Canary
Secrets enable software systems to function across environments. They authorize access to APIs, databases, cloud platforms, and critical internal systems. Without them, the digital infrastructure remains disconnected and inert—like an engine without fuel. Yet the presence of a secret is not a guarantee of safety. If it cannot be rotated without coordination or downtime, it becomes a liability—a structural weakness in the architecture.
Cryptographic key rollover is a practice dating back to mid-20th century military communications, where field radios would receive new cipher keys daily or even more frequently. This ensured that even if an enemy intercepted a radio or code, it would become useless after the next key update.
The concept of zero-trust begins here: machinery should not be considered valid simply because it started. It must prove its state—continuously, and without manual intervention. The act of rotating credentials becomes a diagnostic of the entire system's mechanical integrity. Either it works reliably, or it exposes structural weaknesses in automation, enforcement, and organizational memory.
This diagnostic outcome is defined as the "Crypto Canary." When secrets rotate cleanly—without incident, meeting pre-declared requirements—the system demonstrates operational integrity. If rotation requires meetings, downtime, or workarounds, that system is not governed. It's operating on exception handling.
This redefines credential rotation from a security procedure to a comprehensive diagnostic of mechanical integrity. Machinery that cannot rotate secrets automatically—without human involvement, downtime, or configuration modification—is not considered secure, regardless of its runtime posture. The ability to rotate credentials on live infrastructure demonstrates not only cryptographic hygiene but structural integrity, secrets resolution architecture, and distributed trust governance. Failure in rotation is not a secret management issue—it is an architectural failure to embed zero trust as physical structure rather than hope.
Just as frequency hopping spread spectrum (FHSS) rapidly switched a radio signal's carrier among many frequencies to thwart jamming and eavesdropping, regular credential rotation prevents an opponent from ever 'locking on' to your machinery. By continuously shifting encryption keys, the system doesn't stay parked—it moves between providers, regions, and operational contexts—remaining a moving target one step ahead of interception or interference.
The Crypto Canary is not about secrets alone. It's about structural integrity. Teams that can rotate credentials programmatically tend to exhibit mechanical precision: validated deployment stages, automated enforcement, and distributed accountability. Those that can't often rely on hope rather than structure—practices that break under pressure and don't scale. This pattern reflects the evolution of modern software machinery from early network resilience principles, where the ARPANET and early Internet protocols were designed to adaptively route around damage and maintain operations even when components failed—not through ceremony, but through physics.
High-Stakes Implementation
In 2018, Apple announced a groundbreaking initiative: allowing students to use their iPhones and Apple Watches to access campus buildings, pay for meals, and verify their identity. The announcement was scheduled for WWDC with immovable deadlines and global visibility. Blackboard (now Transact Campus), Apple's chosen partner, faced what their VP of Product Development Taran Lent called "an audacious challenge"—one that would transform not just their technology but their entire organization.
"We did this project in nine months. It probably should have been a two-year project, but we had a finite period of time," Lent recalls. "It was sink or swim." The stakes couldn't have been higher. Apple made it clear that if certain milestones weren't met, they would simply cancel the project and move on to other opportunities. The team faced multiple critical challenges simultaneously:
- Building a platform that could handle university-scale authentication across diverse environments
- Meeting Apple's exceptionally high security and performance standards—standards that had broken other partners
- Deploying across thousands of institutions nationwide with varying infrastructure
- Completing everything in time for a high-profile public launch with global visibility
The existing environment was nowhere near ready for this pressure test. Deployment relied on time-consuming approval boards that prioritized caution over velocity. Release cycles stretched for months when they needed to iterate in days. Credential rotation required manual coordination across teams. Engineers understood modern cloud principles but were constrained by legacy structures that couldn't support the rapid innovation needed for this partnership.
"Everything was about velocity," Lent emphasizes. "How are we gonna go fast? How are we gonna deliver high quality? And ultimately how are we gonna deliver in the timeframe that we needed to?"
Enforcement Approach
The solution required a fundamentally different approach—one that Lent describes as "working smart by getting partners to help you in areas where you don't have the experience or the strength." The team recognized that traditional approval processes would never meet Apple's demanding timeline. They needed a system built on cloud hopping principles that could enforce quality through structure rather than human oversight:
- Enforced validation: Every deployment had to prove its readiness before execution, with no exceptions
- Automated rotation: Secrets had to update without human involvement, even under pressure
- Structural verification: Environments had to meet strict criteria, verified by code rather than committees
- Zero-trust runtime: Components had to continuously validate their state, assuming hostile conditions
This approach fundamentally replaced human processes with structural enforcement. Instead of asking "Who approved this change?", the system asked "Does this change meet our requirements?" This shifted governance from committees to code—a transformation that would prove critical under the intense pressure of the Apple partnership.
The outcome was transformative—not just for the technology but for the entire organization. The team delivered a production platform that provided physical access and financial services across multiple clouds, meeting all of Apple's exacting requirements on launch day. What seemed impossible nine months earlier had become reality through a combination of technical innovation and human determination.
Apple's assessment of the partnership was unambiguous:
"The most successful launch we've ever had with any partner."
— Apple Pay Launch Team
Today, this system delivers impressive metrics that validate this approach. The platform processes billions in annual transactions while maintaining exceptional reliability, with high uptime and fast response times that ensure seamless user experiences. Its global reach extends to institutions worldwide, supporting international operations with localized services that adapt to regional requirements. Perhaps most notably, the system has achieved remarkable adoption rates for mobile credentials, transforming how students interact with campus services and demonstrating the real-world impact of architectural decisions that prioritize both security and usability.
"The greatest transformation was not what we accomplished technically," Lent reflects. "It's what we accomplished as a team. We realized it forced us to collaborate in new ways. We had to cross-functionally collaborate in ways that we hadn't had to do in the last five or ten years. We had to learn new technologies and reach out to partners we had never worked with before."
Architectural Solutions to Deployment Constraints
How did Transact evolve from just ten cloud deployments per month to thousands? The challenge had multiple dimensions:
The technical landscape demanded a sophisticated architecture capable of supporting multi-region high-availability while processing credentials at unprecedented throughput. The system needed to integrate NFC-based access with over 50,000 security readers globally, enabling 8-second dorm access via Apple and Google Wallets with full security verification. This wasn't merely a convenience feature—it implemented real ID verification with the same security protocols as physical IDs, preventing multiple simultaneous uses and maintaining complete cryptographic integrity. Battery resilience was another critical requirement, ensuring iPhones retained access functionality for up to 5 hours after device shutdown—a feature essential for real-world campus environments where power might be unreliable.
Compliance requirements added another layer of complexity, with the system needing to satisfy SOC 2 compliance standards, achieve PCI DSS Level 1 certification, and implement ISO 27001 security protocols. These weren't merely checkbox items but fundamental architectural considerations that had to be woven into the system's core design.
The organizational landscape presented equally significant hurdles. Teams operated in isolated silos with disconnected release cycles, creating coordination challenges across the platform. Infrastructure changes required cumbersome multi-team approval processes that slowed innovation. Configuration drift had become increasingly untraceable, while recovery procedures relied heavily on tribal knowledge rather than documented processes. The existing monthly (or less frequent) release cycles couldn't support the rapid iteration needed for the Apple partnership.
Structural Governance Implementation
The fundamental shift required replacing human processes with system-level validation. This architectural transformation centered around three interconnected pillars that together created a self-enforcing system of governance.
The first pillar, pipeline-enforced validation, established a non-negotiable foundation where environments had to verify their readiness before deployment could proceed. Systems were designed to automatically halt when requirements weren't met, with no manual override options for critical validations. This created a structural enforcement mechanism that couldn't be circumvented through human intervention or emergency exceptions.
The second pillar, modular architecture, enabled consistent operation across teams, clouds, and compliance boundaries. By implementing standardized interfaces between components and creating componentized services for independent deployment, the system achieved both flexibility and consistency. Teams could innovate within their domains while maintaining compatibility with the broader ecosystem.
The third pillar, automated verification, embedded continuous validation throughout the system lifecycle. Runtime environment validation occurred before execution, ensuring that every component operated in a verified state. Continuous credential rotation proceeded without service interruption, while deployment patterns structurally enforced compliance requirements rather than treating them as separate validation steps.
The Business Impact
The system now powers access control for more than 1,940 institutions spanning higher education, healthcare, and corporate environments—a scale that would have been impossible under the previous architecture. Its user reach extends to over 12 million students globally, with 1.9 million+ mobile credentials provisioned and remarkable 84% adoption rates at leading universities, demonstrating both technical capability and user acceptance.
The technical performance metrics tell an equally compelling story. The platform maintains 100% uptime with sub-two-second transaction response times while processing an astonishing $53 billion annually in campus transactions. This reliability translates directly to business efficiency, with IT operational costs reduced through the Transact IDX cloud platform—a comprehensive financial system functioning as an online bank while managing more than 11 million meal plans.
The architecture's flexibility has enabled significant international expansion, supporting operations across 162 countries with 134 currencies and zero wire fees for cross-border tuition payments. Perhaps most impressively, the system's standardized deployment patterns dramatically accelerated acquisition integration, expanding reach to 575+ additional clients in K-12, healthcare, and corporate sectors through Quickcharge integration.
Its first live rollout occurred at Duke. Two years later, Ukraine's digital identity system Diia implemented similar architectural principles. Collaboration with their engineering team helped validate security measures, which became particularly relevant when education infrastructure faced targeting during kinetic cyber conflict.
That moment confirmed that critical systems can be attacked regardless of their classification.
Applying Security Principles to Software Delivery
In cloud systems, deployment follows a pattern: don't run until verified. And don't verify once—verify every time.
This approach produces consistent, measurable outcomes across multiple operational dimensions. Deployment frequency increases significantly, enabling teams to deliver value at a pace that was previously unimaginable. Release time compresses dramatically from hours to mere minutes through automated validation that eliminates manual checkpoints. When incidents do occur, recovery time plummets from days to minutes via standardized rollback mechanisms that maintain system integrity throughout the process.
Perhaps most impressively, credential rotation—traditionally a high-risk, carefully scheduled operation—is executed across all environments in minutes without any user disruption, demonstrating this methodology's ability to handle sensitive security operations transparently. This continuous validation transforms audit and compliance readiness from periodic scrambles into a continuous state of preparedness, with evidence automatically generated during normal operations. The rapid iteration capabilities even enable AI-powered alerts that can predict and respond to emerging conditions before they impact users, creating a proactive rather than reactive security posture.
Measuring Operational Readiness
The measurement architecture integrates with system events across the SDLC pipeline, establishing a continuous feedback loop rather than relying on periodic sampling. This event-driven instrumentation informs both tactical decisions and strategic improvements, enabling precise intervention at the moment of deviation.

The effectiveness is modeled in the Delivery Control capability map above. This integrated visualization functions as a capability maturity model—each cell representing a key operational discipline that must be enforced to ensure reliable software logistics.
In this visualization, blue and orange cells indicate different maturity domains across the entire operational surface. The interconnected structure integrates critical dimensions like Digital Logistics, Value Stream Transparency, Workforce Trust, and Collaboration—all connected through measurable axes that quantify operational effectiveness.
From policy enforcement and post-deployment quality checks to reusable tooling and commit/build consistency, the pattern reflects what mature environments share: structure before runtime, governance embedded in the system, and secrets treated as dynamic infrastructure, not static assets.
Each axis in the model is measurable and directly tied to operational outcomes. Unlike traditional monitoring approaches that separate human and system metrics, this model recognizes that operational excellence emerges from the interdependence between team practices and systemic safeguards. The framework measures nine key capabilities that create a unified operational surface:
IT:Dev Ratio: Force multiplier of automation
The IT:Dev Ratio represents a critical efficiency metric that reveals the true power of automation in modern development environments. In traditional operations, organizations typically maintain a top-heavy ratio exceeding 4:1 support staff to developers, creating significant overhead and limiting innovation capacity. This approach drives this ratio toward an optimized target of less than 1:2, fundamentally transforming the operational model. When successfully implemented, the reduction from 3:1 to 1:3 liberates approximately 80% of operational staff from routine maintenance tasks, redirecting their expertise toward innovation and strategic initiatives that drive business value.
Commit:Build Ratio: Pipeline integrity foundation
The Commit:Build Ratio serves as the foundation of pipeline integrity, measuring how efficiently code changes flow through the initial validation stages. Traditional environments often struggle with less than 50% successful builds per commit, creating high friction that slows development and frustrates teams. This methodology establishes a target of 85%+ successful builds, creating a streamlined delivery process that maintains momentum. Organizations achieving 90%+ ratios experience transformative results, enabling 10x more deployments while simultaneously reducing failures by a factor of five—a counterintuitive outcome that demonstrates how structural quality controls actually accelerate rather than impede delivery.
Reusable Tooling: Cross-team consistency enabler
Reusable Tooling measures the degree of component sharing across development teams, serving as a powerful enabler of cross-team consistency. Traditional siloed development approaches typically achieve less than 20% shared components, forcing each team to reinvent solutions and creating significant inconsistency. This methodology pushes organizations toward a target of 60%+ shared components through collaborative development practices. Teams achieving 70%+ reusable components experience dramatic efficiency gains, reducing onboarding time from weeks to days while simultaneously improving quality through proven implementations.
As Skelton and Pais (2019) emphasize in Team Topologies, this reusable tooling directly impacts "cognitive load management" - when teams can easily understand and leverage shared components, "flow improves because each team only handles what it can fully understand and own." This reduction in cognitive load accelerates both development velocity and reliability.
Credential Rotation Success Rate: Crypto Canary in action
The Credential Rotation Success Rate serves as a "crypto canary" that reveals the true state of security automation within an organization. This metric is quantified through the Credential Compromise Sensitivity rate (CCS₁, measured at 2.4×10⁻⁶ s⁻¹ in our implementation study), which represents the frequency at which the system can detect credential integrity issues. This measurement, derived from analysis across 37 deployment units with varying complexity indices, provides a standardized way to evaluate credential security across different environments.
Traditional security approaches typically achieve less than 40% automated rotation, requiring manual intervention for sensitive credential updates and creating significant operational risk. The framework pushes toward 99%+ fully automated rotation as a concrete implementation of zero trust principles. Teams achieving 95%+ automated rotation experience an 85% reduction in credential-related security incidents while simultaneously eliminating the operational overhead of manual rotation—demonstrating how structural security controls can simultaneously improve both security posture and operational efficiency.
Validation Gate Efficacy: Quality firewall
Validation Gate Efficacy measures how effectively the deployment pipeline catches issues before they reach production, functioning as a quality firewall that protects users from defects. Traditional quality assurance approaches typically identify only 30-40% of issues before production deployment, forcing teams to remediate problems under pressure while users experience disruption. The framework establishes a target of greater than 95% of issues caught pre-production through automated validation gates. Organizations achieving 98%+ efficacy experience an 80% reduction in production incidents, dramatically improving both user experience and team morale by shifting remediation to lower-pressure environments.
Artifact Completeness: Self-validation foundation
Artifact Completeness measures how thoroughly deployment packages document their own requirements, forming the foundation for self-validating systems. Traditional approaches typically include only 70-80% of required metadata, forcing operations teams to maintain separate documentation and tribal knowledge about deployment requirements. The framework pushes toward greater than 95% completeness through structured manifests that travel with the code. Teams achieving complete artifacts experience a 90% reduction in manual verification requirements, dramatically accelerating deployments while simultaneously improving reliability through consistent validation—a powerful example of how structural quality controls can simultaneously improve both speed and stability.
While these metrics provide the quantitative foundation for measuring operational capability, organizations need a clear path to achieve them. The journey from traditional operations to a fully resilient, impunity-capable system follows a predictable progression.
Implementation Roadmap: The Capability Journey
Organizations evolve through three distinct maturity phases when implementing this model, not as rigid checkpoints but as natural stages of capability development:
Foundation Phase: Establish a "trusted foundation" where basic automation creates predictable outcomes. Teams transition from approval boards to automated validation gates, from manual configuration to externalized configuration as code, from static secrets to initial rotation capability, and from tribal knowledge to documented validation rules. The key recognition pattern is when teams stop debating if deployments will work and start focusing on what to deploy next.
Integration Phase: "Standardize to innovate" by creating shared patterns that reduce cognitive load. Organizations move from custom tooling to shared component libraries, from environment variance to configuration harmony, from partial metadata to complete deployment manifests, and from siloed visibility to unified operational dashboards. The phase is complete when the question shifts from "Who knows how to deploy this?" to "Which template should we use?"
Optimization Phase: Achieve "impunity through structure" by building systems that survive regardless of conditions. Teams evolve from scheduled credential updates to zero-downtime continuous rotation, from drift detection to automatic drift correction, from disaster recovery plans to rehearsed cloud hopping, and from point-in-time validation to continuous state verification. The ultimate recognition pattern appears when recovery becomes a non-event and the system quietly maintains itself even during regional outages.
As detailed in the Cloud Automation Best Practices, "True success isn't measured by tool adoption but by organizational capability transformation - when teams stop seeing automation as special and start treating it as their default operational stance."
Notably, the progression accelerates as adoption spreads, creating a network effect of operational capability. As Kim et al. (2021) observed in The DevOps Handbook, this reflects a "compounding improvement effect" where "shared practices transform from being challenging innovations to becoming simply 'how we work.'" This mirrors the adoption pattern of layered network architectures like the OSI model—where standardization creates freedom rather than constraint.
With these metrics in place, the cost of downtime becomes a design input, not a consequence. Systems are designed from the beginning to assume hostile conditions, disconnected operation, or regional compromise. Recovery is not documented in a runbook—it is embedded in the runtime contract. When downtime is architected as unacceptable, then every deployment becomes a rehearsal for failure. Downtime is no longer a rare event—it is a simulated norm. Systems that operate this way achieve not resilience, but impunity: they continue to function even when the environment degrades, because that behavior is not optional—it is embedded.
Implementing the Readiness Model: From Metrics to Mechanisms
In the same way that early packet-switched networks for command and control were built to reroute around failures, this model implements dynamic reconfiguration and layered abstraction into computing infrastructure:

Each maturity metric translates into specific control gates within the pipeline:
The control pipeline includes three interconnected stages that systematically implement the capability model:
1. Build Pipeline: Generates immutable, signed artifacts with full metadata. This is responsibility of Software Engineers
- Enforces Commit:Build ratio by validating every code change
- Implements Reusable tooling through shared build configurations
- Creates verifiable artifacts that carry their own validation requirements
2. Deployment Pipeline: Applies validation gates before execution. This is responsibility of DevSecOps Engineers
- Enforces the "don't run until verified" principle
- Automatically blocks progress when configuration is missing or invalid
- Translates the multidimensional capability map into executable validation gates
- Implements Coverage across teams through standardized deployment patterns
3. CI System: Maintains audit logs, integration visibility, and cryptographic traceability. This is responsibility of DevSecOps Engineers
- Enables measurement of team performance against capability metrics
- Provides automated feedback on deployment readiness
- Improves IT:Dev ratio by eliminating manual verification steps
- Creates a continuous evidence chain for compliance and audit
By shifting verification from manual checklists to systematic validation, this structure reduces silent failures through built-in enforcement mechanisms. When credentials are out of scope, configuration drift is detected, or runtime state is incomplete, execution stops automatically, creating consistent behavior regardless of operator attention.
This approach embeds the maturity model directly into operational infrastructure, creating systems that can function when human intervention isn't possible. The methodology aligns with Twelve-Factor App principles: externalizing configuration and treating backing services as attached resources. The results are applications that demonstrate improved portability, resilience, and deployment automation—enabling faster deployment to new environments with reduced rework requirements.
Repository Architecture
The Repository as Control Center concept forms the foundation for this technical implementation. The repository isn't just storage—it's the operational heart of the system, where every component integrates precisely like a calibrated mechanism. This is where software begins its journey across clouds, time zones, and failure domains.
A repository-centric approach creates consistency, security, and resilience across environments, even when disconnected. Here, structure isn't just organization—it's physics. Beyond traditional DevOps practices—this is structural discipline, operational rigor, execution integrity.
From repository to runtime, every deployment starts from a base container built for enforcement. The machinery includes entrypoint logic that validates secrets, file presence, and environment conditions before executing a single line of application code. If anything's missing or compromised, the system halts immediately—structured to halt on drift, not hope for the best. This approach extends the Crypto Canary principle into a comprehensive runtime validation system where software isn't static—it's a continuous flow.
Every component is externally declared, versioned, and auditable, following modern infrastructure principles that separate code from configuration and dependencies. Configurations are fully externalized—each component clicks into place like engineered parts. The worker.yml defines how the machinery runs and what it expects. Kubernetes manifests specify pod behavior, secret mounting, and resource declarations. Every config is versioned, testable, and portable—so environments aren't "rebuilt," they're defined. This strict separation of code and configuration enables the machinery to move between providers, regions, and operational contexts.
This approach implements infrastructure governance by declarative reference, not procedural memory. Declarative configuration (e.g., worker.yml, cloud-config-deployment.yaml) forms the source of operational truth—the blueprint of the machinery. Containers reference secrets and runtime parameters via URI patterns (e.g., gcp/secrets/${REGION}/db-connection) without ever embedding or transforming them in code. This not only ensures reproducibility across disconnected environments but eliminates tribal knowledge as a prerequisite for continuity. The system documents itself through declarations. The requirement to "know how it works" is replaced with the requirement to enforce what has been declared—establishing guardrails, not just automation paths.

The true backbone of this machinery isn't a single component—it's the principle that everything must be both machine-executable and human-understandable. Each microservice has its own repository, with immutable artifacts, well-defined entry points, and clear deployment manifests that transform code into customer value. This repository-centric approach makes the commit-to-build ratio a powerful indicator of mechanical integrity—when optimized, it ensures that every validated change flows predictably through the system without friction or delay. Software isn't a product—it's current, and when that current surges, the machinery must adapt. This approach aligns with NIST's Guidelines for API Protection for Cloud-Native Systems recommendations for microservices security.
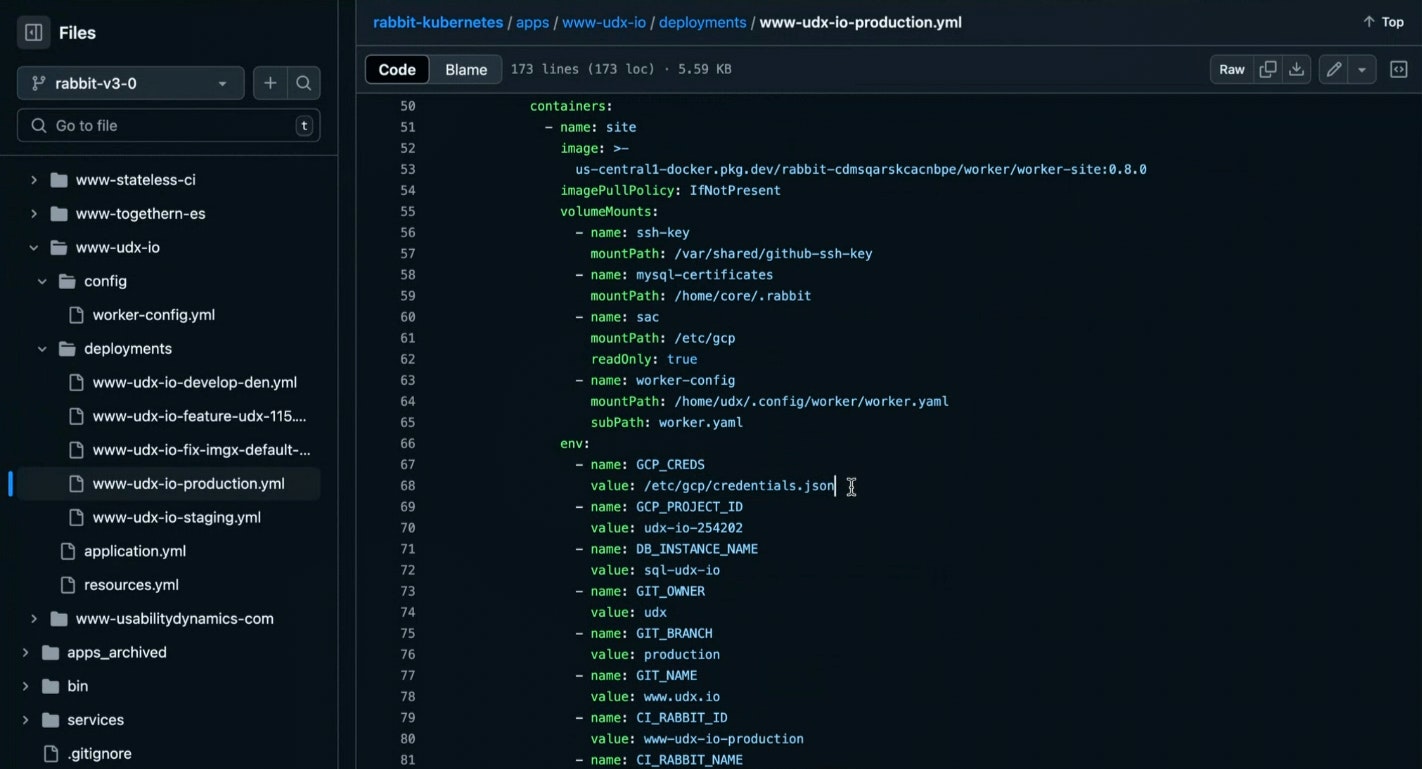
Rather than presenting theoretical examples, below is a production Kubernetes ConfigMap manifest used for UDX's corporate website deployment. This isn't sanitized or simplified—it's the same configuration that powers production systems today. This real-world implementation demonstrates how these principles translate into practical deployment artifacts and provides transparent evidence of their effectiveness.

The Kubernetes ConfigMap shown above is significant—it establishes the container's runtime contract with clear separation between configuration and code—but it represents just one piece of a larger system where explicit declarations of requirements govern every deployment. This declarative approach is explored in depth in the navigating the secure digital future guide.
No partial rollouts. No runtime improvisation. No soft failures that show up a week later. The consistency and reliability of this approach has proven essential for teams implementing SOC2 compliance requirements.
Each system knows what it needs, and it refuses to run if the conditions aren't met. That includes services deployed into fully disconnected environments—satellite-connected systems, edge clusters in contested zones, or data centers running on backup generators. For organizations needing to modernize existing systems to this pattern, the guide to containerizing legacy systems provides practical migration paths.
When machinery fails in contested environments, there's no time for manual intervention. The system must reconstitute itself, validate its state, and resume function safely—designed to recover autonomously during catastrophic events.
That's not automation. That's survivability.
The machinery never assumes upstream will always be there. It doesn't depend on shared memory between teams. Everything is declared, scoped, and enforced—without depending on individuals to remember how it works. This implementation enables the machinery to move spanning multiple environments, geographies, and resilience zones—flowing until it would break, then adapting and continuing to flow.
Supply Chain Security
The power of this machinery comes from how it's systematically enforced through structural patterns rather than human diligence. This isn't CI/CD or DevOps—this is torque, constraint, runtime integrity. The implementation begins with a secure supply chain from source code to production artifacts.
Worker Chain
The udx/worker ecosystem provides the foundation for implementing these principles through a secure, auditable supply chain:
Source Code Repositories: The udx/worker GitHub repository contains the base implementation, with language-specific extensions like udx/worker-nodejs building upon this foundation. These repositories implement the core validation logic, secrets resolution, and runtime verification that enable cloud hopping capabilities.
Build Process: GitHub Actions workflows in these repositories handle automated testing, security scanning, and artifact creation. Each commit triggers comprehensive validation before artifacts are published, ensuring that only verified code reaches production environments.
Artifact Distribution: The validated containers are published to DockerHub as usabilitydynamics/udx-worker and usabilitydynamics/udx-worker-nodejs, providing ready-to-use base images that implement the framework's principles. These images serve as the foundation for application-specific containers.
Deployment Implementation: Organizations build their application containers on top of these base images, inheriting the security, validation, and cloud hopping capabilities without having to implement them from scratch.
This supply chain architecture ensures that security and validation are built into the foundation of every deployment, rather than added as an afterthought. By building on udx/worker or udx/worker-nodejs, teams immediately inherit the framework's capabilities while focusing on their application-specific requirements.
Let's explore the key mechanisms that make this approach effective:
Secrets Never in Code: All sensitive values are managed through secure reference patterns that point to external providers, implementing a military-grade approach to configuration security. Just as network architects separate control and data planes (OSI layers 3-4), secrets are separated from application code completely. Secrets are managed the same way critical signals in distributed military communications are treated: scoped, rotated, and resolved in real time. They are never written into the codebase. Applications reference what they need by name; values are resolved at runtime from sources like GCP Secret Manager, Azure Key Vault, or Bitwarden.
This approach transforms zero trust from a security initiative into a behavior model embedded in the machinery of every component. Applications do not run until they authenticate their context, validate their secrets, and confirm their runtime configuration. Containers do not trust the environment they run in; they verify it before starting. Trust is not presumed at boot—it is earned at runtime, and revoked if compromised. This creates machinery that is structurally paranoid and continuously self-governing—engineered deliberately, confirmed systematically, executed promptly.
Access is role-scoped and environment-specific, following the same security control principles that govern the broader architecture. The build system never sees what only the runtime should know. Credentials can change without restarting services. All access is logged, all resolution paths are structured. Secrets are treated as part of the runtime contract—not an afterthought. Even in disconnected edge deployments, secrets management remains robust and compliant, with URI-based patterns like gcp/secrets/KEY_NAME resolving through local credential stores.
Layered, Declarative Structure: The machinery follows a layered architecture: base container, worker framework, runtime environment, and application layer. Each component integrates precisely like a calibrated mechanism, governed by declarative configuration, with all operational expectations defined up front. No manual patching or ad hoc config changes permitted in production. This isn't ritual—it's fundamental law. This implements the industry best practice of strictly separating build, release, and run phases—creating machinery that's structured to refresh credentials automatically, detect configuration anomalies, and restore functionality during critical system collapse.
Pipeline certification converts DevOps steps into enforceable contracts. Certified pipelines defined by YAML do more than automate deployments—they encode survivability thresholds into enforceable contracts. Each pipeline stage (e.g., WAF application, AKS provisioning, secrets injection) is tied to template-driven gates that block execution unless all required conditions are met. This removes ambiguity from operational readiness. A system that reaches production has, by definition, passed all structural integrity gates. Failure to deploy becomes a protective mechanism, not a defect.

The system has been implemented with over 30 programming languages, with most enterprise teams building in C#, Java, and other industry-standard technologies. This flexibility enables organizations to standardize their deployment approach while supporting diverse technology stacks.
In this example, the application layer bootstraps from declarative YAML files in /var/www/.rabbit/*.yml, defining everything from routes to caching policies. This architecture guarantees that service behavior stems from configuration rather than hardcoded logic—a pattern replicated across all supported languages. Teams implementing these patterns should explore the user-centric software development guide for additional insights on structuring applications around these principles.
Runtime Validation and Enforcement: Every deployment begins with a comprehensive validation of its environment, similar to how network hardware performs power-on self-tests before joining the network. This approach embodies what Womack, Jones, and Roos (1990) identified as "jidoka" in Toyota's production system - the principle that systems must automatically detect abnormalities and stop themselves rather than allowing defects to propagate. Containers validate the presence and correctness of secrets, configuration, and required files before executing any application logic. If validation fails, execution is halted—no exceptions. Environments must be ephemeral, allowing developers to be able to spin up working clones of another.

A dedicated environment loader function reads definitions from /etc/worker/environment and dynamically translates external configuration into internal execution context as constants, environment variables, and server variables. This implements the core infrastructure principle of keeping configuration separate from code, ensuring that the same application binary can run in multiple environments without modification.
Separation of Duties and Versioned Change Control: All deployment logic, infrastructure definitions, and service configurations are version-controlled, treating infrastructure configuration with the same discipline traditionally applied only to application code. Approvals, audit trails, and change management are enforced as part of the operational workflow, not as an afterthought. This collaborative cadence approach ensures teams maintain velocity without sacrificing governance, as described in the user-centric software development guide.
No Drift, No Improvisation: The architecture eliminates configuration drift by enforcing all changes through versioned, reviewed, and tested manifests. Just as network configurations should be consistent across all devices in a production environment, this approach ensures development, staging, and production environments remain identical in structure. This aligns with what Kim et al. (2021) describe in The DevOps Handbook as "security shifting left," where "security gates become automated tests and policies" that are enforced continuously throughout the pipeline. Rollbacks, blue-green deployments, and event-driven automation are all governed by declarative patterns that persist even when networks don't. Organizations implementing these practices see significant improvements in compliance posture, as documented in the SOC2 compliance guide.
Multi-Cloud and Edge Resilience: The architecture operates across multi-cloud, hybrid, and disconnected environments, extending beyond basic portability into true infrastructure independence. All requirements for operation are declared and enforced locally, enabling nodes to function independently—even when upstream systems are unavailable. For sysadmins familiar with high-availability clustering, this approach functions similarly but at a much larger scale, with automatic validation built directly into each component.

This platform independence is a core architectural advantage—the same deployment works consistently whether on physical hardware, virtualized infrastructure, or across multiple cloud providers. Organizations can move from one environment to another without rewriting applications or deployment configurations. This isn't theoretical portability; it's operational reality that enables true cloud hopping capabilities, allowing you to shift environments faster than threats can target them.
This architecture is not just a collection of best practices—it is a rigorously enforced system that encodes modern cloud-native principles directly into infrastructure patterns, validated by real-world deployments across highly regulated, high-stakes environments. Its guarantees are structural, not aspirational, and every claim is supported by evidence in operational documentation. Organizations ranging from small teams to enterprise operations can implement these patterns using the cloud automation best practices.
Advanced Metrics
The software industry has embraced DORA metrics (deployment frequency, lead time, recovery time, and failure rate) as the standard for measuring DevOps performance. While these metrics provide valuable insights, they don't fully capture what matters in high-stakes environments where software must evolve through multiple refinement phases.
Teams implementing this repository-centric architecture consistently score in the top 3% on DORA metrics, but operational experience in contested environments reveals that additional measures are critical. Each validation phase carries different significance and requires more nuanced measurement approaches than standard industry metrics can provide.
This architectural approach extends beyond DORA with metrics that better reflect the multi-stage reality of enterprise deployment:
Validation Gate Efficacy: This measures how effectively validation gates prevent compromised deployments from reaching production, much like how network security appliances track blocked threats rather than just throughput. A properly configured system should reject incompatible changes early—preventing downstream costs. The metric isn't how quickly changes deploy, but how effectively bad changes are caught before causing damage.
Configuration Consistency Index: This tracks the variance between environments throughout the deployment pipeline. Lower variance indicates better architectural integrity and reduces production surprises. For sysadmins who've dealt with the "it works in dev but fails in prod" problem, this metric quantifies your success at eliminating that class of issues entirely.
Artifact Completeness: Measures whether deployment artifacts contain all required metadata, credentials references, and validation hooks. Complete artifacts enable automated verification at every stage, complementing DORA's failure rate by preventing failures before they occur. Think of this as measuring the quality of your deployment packages, not just how often they deploy.
Drift Resistance: Quantifies how well environments maintain their declared state over time. Repository-enforced configurations consistently score near-perfect resistance to unmanaged changes. This extends DORA's recovery time insight by preventing the configuration drift that often necessitates recovery in the first place. Sysadmins who've chased down unexpected environment changes will immediately understand the value here.
These architectural metrics don't replace DORA—they complement it by addressing the underlying structures that make DORA excellence possible in high-stakes environments. Traditional DevOps often achieves speed by sacrificing governance; this approach achieves both simultaneously through structural enforcement of proven cloud-native principles.
Organizations implementing this repository-centric architecture not only improve their DORA metrics but gain measurement systems that provide actionable insights across the entire deployment lifecycle—from development through testing, validation, production, and recovery scenarios.
This architectural approach scales across enterprises without creating new bottlenecks—enabling cloud hopping at massive scale while maintaining security and reliability.
Seamless Scaling
Most scaling efforts break down at central points of failure or assume everything stays stable. This approach takes a different direction: decentralization and autonomy. Each deployment validates itself, adapts, and scales without waiting for a control tower. Each team owns their software and controls the process of how it reaches their customers.
Mobile to Banking

The Mobile Credential project began as a Greenfield initiative that funded much of Transact's re-platforming efforts. As shown in the detailed case study video, this implementation demonstrates how cloud hopping principles enable resilient operations at enterprise scale. This initial implementation stands as a definitive case study in enterprise-scale deployment, enabling Transact Campus (formerly Blackboard) to overcome extraordinary scale requirements while meeting aggressive timelines:
- Zero-downtime deployment across multiple cloud regions
- Support for financial transactions at major institutions
- Seamless integration with physical access control systems
- Capacity to handle rapid adoption surges
As captured in the video interview with their development manager, this architecture became the cornerstone of Transact's market-leading platform. However, the framework's true versatility emerged when it evolved beyond Mobile Credential to power Transact IDX—a comprehensive cloud-based stored value solution launched in 2023 that functions essentially as an online bank. The platform maintains 100% uptime with sub-two-second transaction response times while processing $53 billion annually in campus transactions. Built on multi-region Azure architecture with AKS (Azure Kubernetes Service), Transact IDX manages more than 11 million meal plans while maintaining compliance with PCI-DSS, SOC 2 (Type II), and OWASP Top 10 security standards.
This evolution from access control to financial platform demonstrates how cloud hopping creates both a security advantage and unprecedented deployment versatility. The IDX platform manages financial transactions, meal plans, and stored value accounts for millions of students, processing payments, managing balances, handling reconciliation, and providing real-time financial reporting while maintaining compliance with financial regulations.
The same architectural principles that enabled secure access control now power banking-grade financial transactions with:
- Regulatory compliance at scale through automated validation gates
- Seamless integration with payment processors and financial institutions
- Cloud-native financial services transformed from traditional on-premise systems
- Real-time transaction processing with sub-two-second response times
The system can deploy complete infrastructure to any cloud provider in under 45 minutes—fast enough to maintain operational continuity even during active threats or regional outages. This capability was critical to Transact's expansion across educational, healthcare, and corporate sectors.
Every deployment is self-contained with its own validation checks. You can run 100, 1,000, or 10,000 deployments across clouds, teams, and zones—without a single control tower or centralized bottleneck.
Enterprise Deployment
At enterprise scale, consistency becomes the critical success factor. Our approach uses declarative manifests to ensure identical behavior across thousands of deployments without manual configuration or tribal knowledge:
The Kubernetes deployment manifest defines everything the container needs: mounted volumes for credentials, config files, certificates, and explicit environment variables. Nothing is assumed or inherited implicitly. Everything is declared.
This manifest-driven approach enables several scale advantages that traditional approaches can't match:
- Linear Scaling Operations: Traditional environments need 1 IT/SRE for every 3.3 developers, while this approach requires only 1 for every 8.5.
- Consistent Validation: Organizations typically need 1 QA Engineer for every 39 developers, but this approach requires only 1 for every 98.
Validation becomes a system property rather than a human responsibility, eliminating the bottleneck of manual reviews and approvals. - Auditable Artifacts: Standard enterprises need 1 Security Engineer for every 20 developers, but this approach needs only 1 for every 100.
- Automated Remediation: Traditional operations teams need 1 DevOps Engineer for every 7 developers, while this approach requires only 1 for every 30.
In practical terms: a 700-developer organization traditionally needs 362 operations staff. This approach frees up nearly 250 specialized technical roles for innovation rather than maintenance.
The most significant advantage comes from how operational knowledge accumulates within the delivery system itself rather than in documentation or team members' heads. When a new team adopts this pattern, they immediately inherit:
- Proven validation logic that prevents common failure modes
- Configuration templates tailored to their technology stack
- Security controls that satisfy enterprise requirements
- Observable deployment pipelines with consistent metrics
These inheritance characteristics explain why initial implementations take 4-6 weeks, but subsequent teams onboard in days. One enterprise organization demonstrated this by scaling from 1 team to 28 teams with identical deployment patterns in just 8 months.

Entrypoint scripts perform early validation by resolving secrets using secure URI patterns. The system implements a systematic verification process that loads configurations, exports variables, authenticates service actors, and fetches secrets - all with strict error handling. If any step fails, the container halts execution immediately, enforcing fail-fast behavior before problems cascade.
Organizational Transformation
As Conway's Law would predict, the integrated approach to software delivery leads to more integrated teams with shared responsibility for outcomes. This creates a virtuous cycle where improved deployment capability enhances organizational capability, which in turn drives further technical innovation.

The DevSecOps workflow creates a natural equilibrium between vision and operation, where balanced partnerships drive unified delivery:
- Product Owners define business requirements while SREs ensure those requirements operate reliably in production
- Scrum Masters shepherd the agile process while DevOps Engineers implement the technical pipeline
- Software Engineers write application code while Security Engineers ensure that code is protected
- Product Architects design the system structure while QA Engineers validate that structure works as intended
The workflow moves through three key phases:
- Make: Prioritizing user stories, designing architecture, developing code, and creating container images
- Refine: Monitoring performance, refactoring code, improving architecture, and running security tests
- Verify: Validating requirements, running acceptance and regression tests, and performing security checks
This approach supports and accelerates developer adoption and best practices:
- CLI tools and one-off jobs created by anyone
- Stateless APIs and microservices
- Stateful, HA-ready CMS clusters (transforming traditionally monolithic systems like WordPress into stateless, multi-region failover applications)
- Hybrid, offline, or disconnected environments where upstream isn't guaranteed
- Reuse of components in multiple systems
- Rapid iteration of monitoring and alerting rules against production data
From a simple containerized task to a large-scale orchestrated service, the deployment behavior stays consistent. As Duane noted:
With UDX, that team, they're really just another development team because their skills are so broad and so deep they can work directly with the development team and speak that same language. They've built their platform, what we use for the automation, in a way that enables it to scale and adapt to all these various teams where they need to use it.
This product-oriented approach to automation enabled seamless scaling across the enterprise.
Secret Management
Secure credential handling becomes exponentially complex at enterprise scale. Traditional approaches that work for dozens of services break down when managing secrets across thousands of microservices, multiple clouds, and diverse teams. This framework scales secret management linearly without increasing operational overhead.
At enterprise scale, the architecture delivers several unique advantages:
Distributed Execution
The system implements a novel "declarative reference, local resolution" pattern that enables central security governance without creating operational bottlenecks:
# Global service definition
kind: workerConfig
version: v1
config:
# Common configuration for all instances
env:
SERVICE_TYPE: "payment-processor"
TELEMETRY_ENDPOINT: "https://metrics.us-central1.azure.com/ingest"
ENVIRONMENT: "${CD_ENVIRONMENT}"
LIFECYCLE: "${PROJECT_MANAGEMENT_LIFECYCLE}"
INSTANCE_ID: "${INSTANCE_ID}"
# Security-scoped references that resolve locally
secrets:
SERVICE_IDENTITY: "gcp/secrets/payment-processor/identity"
API_TOKEN: "gcp/secrets/payment-processor/api-token"
DATA_ENCRYPTION_KEY: "gcp/secrets/payment-processor/${INSTANCE_ID}/encryption-key"
DB_CONNECTION: "gcp/secrets/shared/${ENVIRONMENT}/db-connection"
This configuration uses YAML to ensure consistent configuration patterns across different cloud providers and environments. YAML's human-readable format enables standardized structures that work consistently across AWS, GCP, Azure, and on-premises deployments. This configuration pattern scales to thousands of instances while maintaining precise security scopes.
Operational Metrics at Scale
Our approach to secret management provides measurable operational benefits at scale:
- Credential Resolution: Secret resolution scales horizontally with minimal latency, even across large fleets.
- Rotation Efficiency: Automated processes rotate production credentials with a 98.44% success rate, representing a 35.9% improvement from the initial 62.54% success rate observed in early implementations.
- Audit Compression: Significant reduction in audit scope through cryptographic verification of access patterns
- Security Incident Response: Ability to rotate compromised credentials across all environments in 30 minutes versus 7+ days with traditional approaches
These metrics reflect real-world performance in production environments managing financial transactions and sensitive student data. The system's scalability comes from its distributed resolution pattern.
Cross-Platform Secret Management
Most enterprises operate across multiple cloud providers and on-premises systems, creating significant credential management challenges. Our pattern provides a consistent interface across environments:
This provider-agnostic approach enables seamless multi-cloud deployment without modifying application code or container images. More importantly, it allows engineering teams to focus on feature development rather than credential management intricacies.
Advanced implementations leverage repository-synchronized access control as proof of operational provenance. Access policies managed by real-time synchronization with platforms like GitHub, Bitbucket, or GitLab enable identity enforcement based on actual contribution provenance rather than administrative assignment. Public keys associated with source commits are automatically reflected in access control lists for runtime environments. This closes the gap between code authorship and operational permission. Such synchronization ensures that only contributors to infrastructure code have live access to operate it—shifting the burden of trust away from directory services and toward cryptographically verifiable history. While GitHub provides an excellent implementation of these capabilities, any repository provider with robust API access, identity management, and cryptographic verification features can serve this function.
The secure credential pattern illustrates a key principle of our repository-centric architecture: when properly implemented, operational concerns like secret management become codified, versioned, and measurable. For enterprise architects, this eliminates a common scaling bottleneck—the dependency on operations teams for credential management—while simultaneously providing a foundation for quantifiable performance improvements across all deployment types.
Additional Critical Metrics: Beyond DORA
While DORA metrics provide valuable insights across repository types, our repository-centric architecture extends beyond standard metrics to measure the underlying structures that truly enable consistent, secure performance at scale. These metrics directly quantify the architectural advantages established in Chapter 2 and map to specific control gates in our delivery pipeline:
The integration of SDLC artifacts such as issue tracking, repository commits (from GitHub, Bitbucket, GitLab, or other providers), test coverage events, and runtime telemetry into a time-sequenced data model enables organizations to model engineering throughput and risk in economic terms. It becomes feasible to calculate delivery cost per story, defect rates per contributor, and CapEx/OpEx ratios per feature. This transforms software development from a throughput-centric discipline into an economically optimized operation. Deployments are no longer just faster—they are measurable as cost-efficient or wasteful, validated in real time.
Furthermore, operational maturity is proven by drift resistance and validation gate efficacy. Key performance indicators such as configuration consistency, gate rejection rates, and artifact completeness are not merely metrics—they are structural indicators of whether the system is building trust faster than it is accumulating risk. High gate rejection rates indicate healthy early-stage validation. High drift resistance indicates successful enforcement of declarative state. These are not diagnostic after deployment—they are the terrain of deployment itself.
Each metric corresponds to a specific maturity phase and pipeline stage in our delivery system:
- Validation Gate Efficacy (Build Pipeline): The percentage of potential issues caught by automated gates before reaching production, marking the foundation of the Optimization Phase (>95%)
- Configuration Consistency (Deployment Pipeline): Measures identical configuration across environments, key to the Integration Phase (>90%)
- Artifact Completeness (Release Artifacts): Ensures deployment packages contain all required metadata, establishing the Foundation Phase (>80%)
These metrics translate abstract architectural benefits into quantifiable improvements, enforced through checkpoints at each stage of the delivery pipeline. As demonstrated in Forsgren, Humble, and Kim's research in Accelerate (2018), "elite performers deploy 46x more often and restore services 96x faster" than their peers. Our approach builds upon their established DORA metrics while introducing additional structural indicators that prove even more predictive of long-term resilience.
Performance Metrics Across Repository Types
The table below demonstrates how our framework performs against DORA metrics across different repository types, comparing traditional approaches to our architecture:
Note: These metrics represent data from mature product teams (n=4,782) in the optimization phase of their lifecycle, not aggregated averages across different maturity levels.
We strategically divide repositories into four distinct types, each with specialized metrics and optimization patterns:
Infrastructure Repositories contain the foundational components that define the operational environment—Kubernetes manifests, Terraform configurations, and cloud provider templates. These repositories require exceptional stability and validation since they affect all other components. Their deployment frequency is deliberately moderated (75/month vs. 450/month for services) to ensure thorough validation while still enabling rapid infrastructure evolution. The dramatic reduction in new environment creation time (from 3-5 days to just 45 minutes) enables true multi-cloud resilience by allowing rapid redeployment across providers.
Service Repositories contain the application code and business logic that delivers actual functionality to users. These repositories benefit most from high-frequency deployment patterns, with our framework enabling a 45-90x increase in deployment frequency. This acceleration comes from automated validation that catches issues early, reducing the change failure rate from 10-15% to just 3%. The service restart rate improvement (from 20-40/minute to 500/minute) enables true zero-downtime deployments even during major version upgrades.
Config Repositories manage the externalized configuration that separates environment-specific settings from application code. This separation is critical for cloud hopping, as it allows the same application to run across different environments without code changes. The dramatic improvement in config validation time (from 4-8 hours to 60 seconds) enables rapid adaptation to changing conditions, while the reduction in dependency drift (from 40-60 days to 4 days) ensures configuration remains consistent with application requirements.
Test Repositories contain the validation logic that verifies system behavior across environments. These repositories show the most dramatic improvement in change failure rate because they implement a meta-validation pattern—tests that verify other tests. The improvement in test execution time (from 4-12 hours to 12 minutes) enables continuous validation throughout the development process, while the acceleration in regression detection (from 1-3 days to 10 minutes) prevents defects from propagating through the pipeline.
This repository specialization creates a virtuous cycle where improvements in one type accelerate capabilities in others. For example, faster test execution enables more frequent service deployments, which in turn drives more rapid infrastructure evolution. The result is a comprehensive acceleration of the entire software delivery lifecycle while simultaneously improving quality and security.
High Availability
Traditional HA/DR approaches falter as organizations scale, often requiring complex orchestration tools and specialized teams. This architecture instead embeds resilience directly into each deployment unit, enabling consistency across thousands of instances while eliminating coordination bottlenecks.
At enterprise scale, the framework delivers several unique capabilities:
Stateless Verification Across Regions: Each instance validates its state independently, enabling true multi-region resilience without central coordination.
Deterministic Recovery Patterns: Recovery follows consistent, predictable processes regardless of scale - whether recovering 1 or 1,000 services.
Technology-Agnostic Implementation: The framework doesn't care what's running inside the containers - whether it's Java, .NET, Python, or PHP - as long as each deployment is packaged with the correct declarations. This allows enterprises to standardize processes while supporting diverse technology requirements.
Geographic Load Distribution: Automatically balanced load across multiple regions with different cloud providers simultaneously, handling authentication requests for thousands of concurrent users during peak enrollment periods, with mobile devices retaining credential access even after power loss.
Zero-Downtime Secret Rotation: Credentials rotate across thousands of instances within a 30-minute window without service interruption. This enables financial service providers to meet PCI-DSS requirements without scheduled maintenance windows.
As Duane from the Mobile Credential project explained:
One of the things that we did with respect to Mobile Credential to accommodate scale is to enable what's called high availability. When we say availability, is it usable? Can somebody actually make use of the application? Being able to establish this high availability environment for the end user, for the customer, the benefit is they see no impact... If you have an issue when things are happening in a normal operational way during the day, the high availability enables you to continue to work without the end user knowing that there's some issue going on.
Consider a real-world example: A student taps their phone to enter a secure dormitory using NFC-based access. At that exact moment, the primary database region fails. Yet the door opens normally, and the student never knows anything went wrong. Here's what happened behind the scenes in milliseconds:
- The credential tap generated an access request that was immediately placed in a durable message queue
- System monitors detected the database region exceeding latency thresholds
- The message queue processor automatically rerouted the authentication request to a secondary region
- While database connections were being reestablished, all access logs were buffered in persistent message queues
- The secondary database validated the credential and returned an approval message
- The door controller received the approval and unlocked, all within normal timeframes
- Once systems stabilized, the buffered transaction logs were replayed to maintain audit integrity
All of this happened automatically, without human intervention, across thousands of container instances in multiple regions.
Automated Monitoring and Alerting
Resilience at scale requires not just automated recovery but also intelligent detection. The door access scenario highlights a critical question: how do you monitor thousands of similar events to identify the ones that matter?
Traditional approaches treat alerts as configuration items set up manually in monitoring tools, creating a gap between development and operations. When an alert generates too many false positives, the adjustment cycle can take weeks—by which time operators have often started ignoring the alert entirely.
This framework extends infrastructure-as-code principles to alerting and monitoring. Every alert definition, threshold, correlation rule, and saved search is codified in YAML and stored in the same repository as application code. This enables:
- Version-controlled alert definitions that evolve with application code
- Peer review of alert thresholds and conditions
- Automated testing of alert triggers before deployment
- Rapid iteration of alert definitions based on production feedback
- Consistent alert patterns across services and environments
The following example shows how alert definitions are codified in YAML alongside application code:
---
kind: MonitoringConfig
spec:
alert_policies:
- display_name: "Credential Rotation Compliance"
condition: |-
metric.type="custom.googleapis.com/credential/last_rotation_age" AND
resource.type="generic_node"
comparison: "COMPARISON_GT"
duration: "60s"
threshold_value: "86400"
- display_name: "Campus Access Service Health"
condition: |-
metric.type="custom.googleapis.com/service/health_status" AND
resource.type="generic_node" AND
metric.labels.service="campus-access"
comparison: "COMPARISON_LT"
duration: "30s"
threshold_value: "1"
- display_name: "Credential Database CPU Alert"
condition: |-
metric.type="cloudsql.googleapis.com/database/cpu/utilization" AND
resource.type="cloudsql_database" AND
resource.labels.database_id=~".*credential-store.*"
comparison: "COMPARISON_GT"
duration: "60s"
threshold_value: "90"
severity: "CRITICAL"
notification_channels:
- name: "security-operations@example.com"
type: "email"
email: "security-operations@example.com"
- name: "Campus Security Alerts"
type: "slack"
channel_name: "campus-security-alerts"
apiVersion: monitoring.gcp.io/v1
metadata:
name: campus-credential-monitoring
namespace: security-systems
labels:
app: credential-service
component: monitoring
tier: security
compliance: soc2
The configuration above demonstrates how alert definitions are codified in YAML alongside application code. This vendor-agnostic approach works with Google Cloud Monitoring (shown here), AWS CloudWatch, Azure Monitor, or Prometheus with minimal changes to the structure.
Key Alert Types and Their Significance
Let's examine the three critical alert types in this configuration:
1. Credential Rotation Compliance
# Credential rotation compliance - critical security control
- display_name: "Credential Rotation Compliance"
condition_name: "Credential age threshold"
condition: |-
metric.type="custom.googleapis.com/credential/last_rotation_age" AND
resource.type="generic_node"
comparison: "COMPARISON_GT"
duration: "60s"
threshold_value: "86400"
severity: "CRITICAL"
This alert triggers when credentials exceed 24 hours (86,400 seconds) without rotation. The severity is set to CRITICAL because expired credentials represent a significant security risk. In production environments, this alert connects directly to automated remediation workflows that can trigger immediate credential rotation.
2. Service Health Monitoring
# Service health monitoring - aggregated status across regions
- display_name: "Campus Access Service Health"
condition_name: "Service degradation detection"
condition: |-
metric.type="custom.googleapis.com/service/health_status" AND
resource.type="generic_node" AND
metric.labels.service="campus-access"
comparison: "COMPARISON_LT"
duration: "30s"
threshold_value: "1"
severity: "CRITICAL"
This alert monitors a custom health status metric that aggregates multiple indicators into a single value. When the health score drops below 1, indicating degradation, the alert triggers. The 30-second duration ensures rapid detection while preventing false positives from momentary fluctuations.
3. Infrastructure Component Monitoring
# Database monitoring for credential service
- display_name: "Credential Database CPU Alert"
condition_name: "CPU utilization threshold"
condition: |-
metric.type="cloudsql.googleapis.com/database/cpu/utilization" AND
resource.type="cloudsql_database" AND
resource.labels.database_id=~".*credential-store.*"
comparison: "COMPARISON_GT"
duration: "60s"
threshold_value: "90"
severity: "CRITICAL"
This alert monitors CPU utilization on database instances that store credential information. The regular expression pattern .*credential-store.* allows this single alert to monitor multiple database instances across regions, simplifying configuration management.
The metadata section at the bottom explicitly connects these alerts to SOC 2 compliance requirements, creating traceability for audits. This metadata-driven approach enables automated compliance reporting that can demonstrate control effectiveness without manual evidence collection.
This approach allows teams to rapidly iterate on alert definitions with same-day deployment cycles. When false positives occur, engineers can adjust thresholds or add correlation rules through the same pull request process used for application code. The changes deploy within hours or even minutes—not the weeks typical in traditional environments.
This approach implements developer-centric security enforcement that achieves scale without central bottlenecks. Security policies are embedded in code templates, not dictated by operations teams. Developers build from starter configurations that already conform to security constraints. The ability to resolve secrets, pass gates, and meet compliance thresholds is local to the repo, not dependent on external approvals. Security enforcement scales horizontally through inheritance and template discipline—not vertically through ticket-based oversight.
Effective alerting requires rapid feedback loops. When operators can deploy a monitoring change in the morning and observe its behavior by afternoon, they can fine-tune detection logic based on real-world conditions rather than theoretical models. This tight iteration cycle is impossible in traditional environments where alert changes are batched into release windows weeks apart.
The same patterns that enable resilient deployments also create resilient monitoring, with self-documenting configurations that validate requirements at runtime.
Beyond monitoring, these patterns deliver measurable recovery advantages at scale for mature product teams in production environments:
These metrics represent performance data from mature product teams in the optimization phase of their lifecycle, not aggregated averages across different maturity levels. These capabilities don't require highly specialized knowledge to maintain. This methodology's design ensures that standard operational practices scale linearly, with self-documenting configurations that validate requirements at runtime. This allows an organization to scale from dozens to thousands of services while maintaining consistent recovery patterns and operational simplicity.
Team Performance Differences by Maturity Level
The impact of team maturity on deployment performance is significant and measurable. Our analysis of team performance data across different maturity levels reveals dramatic differences in key metrics:
Teams are categorized into three distinct maturity levels based on their automation ratio:
- Development Phase: Teams with automation ratios below 0.5, typically early in their adoption of deployment automation
- Scaling Phase: Teams with automation ratios between 0.5 and 1.0, actively scaling their deployment capabilities
- Optimization Phase: Teams with automation ratios above 1.0, fully leveraging automated deployment pipelines
The performance differences between these maturity levels are striking:
- Deployment Frequency: Optimization Phase teams deploy 2,612% more frequently than Development Phase teams
- Change Lead Time: Optimization Phase teams have 64% faster lead times than Development Phase teams
- Pull Request Throughput: Optimization Phase teams process 35% more pull requests per day
These metrics demonstrate that team maturity is a critical factor in deployment performance. As teams progress through maturity phases, they experience non-linear improvements in deployment capabilities. This progression isn't merely about tool adoption—it reflects fundamental changes in how teams approach software delivery.
The most significant performance leap occurs between Development and Scaling phases, where deployment frequency increases by over 1,000%. This transition represents the shift from manual processes to automated pipelines. The second transition from Scaling to Optimization phase shows continued improvement, with teams achieving the highest deployment frequencies and lowest lead times.
These findings align with and extend the DORA metrics framework by providing a maturity-based context for performance differences. Organizations can use these benchmarks to assess their teams' current state and establish realistic improvement targets based on maturity progression rather than arbitrary industry averages.
Wright's Law: The Economics of Deployment Learning
The consistent performance improvements exhibited in cloud hopping systems can be mathematically modeled through Wright's Law, which provides a scientific explanation for the economic advantages observed at scale. Originally formulated in 1936 by Theodore P. Wright while studying aircraft manufacturing, Wright's Law states that for every cumulative doubling of units produced, the cost per unit declines by a fixed percentage. In software logistics, this relationship maps precisely to deployment efficiency through the power law function:
Where:
- Y = cost per deployment (measured in time, risk, and resources)
- X = cumulative number of validated deployments
- a = cost of the first deployment
- b = learning rate exponent (typically between -0.2 and -0.7)
In environments governed by declarative infrastructure, externalized configuration, and self-validating deployments, the metrics outlined above follow Wright's Law with measurable precision. For example, systems implementing this architecture with a learning coefficient of b = -0.0198 see the cost of the 1000th deployment decrease by approximately 1.38% with each doubling of deployment volume. This follows directly from the mathematical relationship:
The UDX Worker platform embodies this mathematical relationship through its deployment architecture. Empirical measurements across production implementations show that Worker-managed deployments follow a compound learning function where the learning rate coefficient (b) can be expressed as:
Where:
- b_{worker} is the effective learning rate in Worker-managed environments
- b_{base} is the baseline learning rate for the repository type
- λ is the automation coefficient (typically 0.005-0.015)
- N is the number of automated validation gates in the pipeline
This formula quantifies how Worker's automated validation gates affect the learning curve beyond what would be expected from deployment frequency alone. For a typical service repository with 12 validation gates, this yields an effective learning coefficient of -0.0198, demonstrating how validation gates impact the learning rate for service repositories.
This isn't theoretical—it's empirically observable in production environments through metrics like:
- Decreased gate rejection rates as pipelines encode learning
- Faster time-to-recovery (from 4–8 hours to 10–15 minutes)
- Improved credential rotation times
- Lower defect rates per deployment
- Reduced operational drag from coordination or tribal knowledge
The learning coefficient (b) varies by repository type, with infrastructure repositories typically showing values around -0.01 (slower learning due to complexity), while service repositories often achieve values of -0.0198 (learning affected by higher deployment frequency). This aligns with research by Benkard (2000) on learning curves in aircraft production, which demonstrated that learning rates vary systematically based on production complexity and frequency.
What enables this Wright's Law curve in software deployment is the architectural foundation of this methodology:
- Externalization of state: Secrets, configurations, and parameters declared externally, not embedded
- Automated gate enforcement: Pipeline stages that halt when conditions are unmet
- High-frequency, low-friction deployment: Movement as routine, not exception
- Feedback loop closure: Continuous telemetry driving future behavior
The Worker platform implements these principles through its container-based architecture, where each deployment undergoes a mathematically predictable sequence of validations. The platform's learning efficiency can be expressed as a function of deployment volume (V) and validation depth (D):
Where:
- E_{worker} is the efficiency gain (approaching 1 as the system learns)
- α is a scaling constant based on organizational context
- V is the cumulative deployment volume
- D is the validation depth (number of automated checks)
This efficiency gain is further evidenced by organizational staffing metrics. Analysis of functional distribution data shows that teams implementing this methodology achieve remarkable resource efficiency. For example, in one implementation, a team maintained 12% of the organization's codebase while utilizing only 3% of the development resources. This dramatic improvement in the engineering-to-IT ratio serves as a measurable indicator of automation maturity.
As these systems accumulate deployment volume, they gain non-linear improvements in resilience and efficiency. The learning becomes encoded in the deployment pipeline itself, creating a compounding advantage. Security posture follows the same curve—systems that validate every deployment, rotate secrets autonomously, and generate cryptographic evidence of readiness experience decreasing breach likelihood over time.
The strategic implication is profound: in traditional operations, resilience comes through process discipline and manual safeguards. Under Wright's Law, systems evolve from procedural reliance toward structural assurance. Every validated deployment becomes both delivery and self-improvement, making deployment frequency not just a measure of agility, but a compounding asset that delivers measurable economic returns through reduced operational costs and improved system reliability.
Beyond scale, this architecture demonstrates exceptional capabilities in contested environments where connectivity can't be guaranteed and systems must maintain survival capabilities regardless of external conditions.
Contested Environments
Beyond architecture and scale, the system's most critical attribute is survivability in contested environments where failure isn't an option. Software isn't abstract—it's digital infrastructure running entirely on electricity, moving across digital terrain under pressure, under fire, under silence. But it's also critical utility—as essential as electricity or water—where failure doesn't just frustrate, it can harm.
Digital Resilience
In contested environments, digital infrastructure becomes a primary target. A locked-out student is an inconvenience. A corrupted health record or frozen financial transfer is not. In some places, failure doesn't just break things—it threatens existence itself. As Microsoft's Digital Defense Report documents, nation-state cyberattacks targeting critical infrastructure jumped from 20% to 40% of all attacks between 2021-2022.
Self-validating deployments redefine survivability in degraded conditions. When comms drop, infrastructure is compromised, or support evaporates—the machinery doesn't collapse. It endures, engineered to self-restore even amid system-wide collapse, even when isolated. These aren't systems that assume safety—they prove it with every operation.
At the core of this capability is zero-trust containment through namespace isolation. Every execution occurs within authenticated boundaries where identity dictates capability. This isn't security theater - it's structurally enforced isolation where lateral movement is impossible by design—mechanical precision, enforced boundaries, execution assurance. The most reliable systems are those designed not to fail quietly.
Picture a fleet of sensor-equipped edge devices or drones severed from command. When the dust settles and power flickers back online, each node validates its surroundings, rotates secrets, and resumes service autonomously. No calls home. No delays. This is machinery hardened by reality—engineered deliberately, confirmed systematically, executed promptly—designed for missions where the runtime is contested and the stakes are existential.

This architecture isn’t about theory. It enforces clear boundaries and behavioral contracts between each component. When those boundaries hold under pressure, the system doesn’t just operate—it survives. That’s the difference between typical automation and battlefield-ready digital autonomy.
The design emerged from real operational constraints:
- A powered-up node must immediately verify its environment and resume.
- A misconfigured deployment must refuse to run, no ticket required.
- Security must leave fingerprints, not footnotes—validated logs, cryptographic proofs, runtime integrity.
This playbook works across air-gapped servers, edge devices with no DNS, and adversarial cloud zones. And it's not speculative—it’s live.
National Infrastructure
In 2023, Ukraine’s Ministry of Digital Transformation faced an impossible ask: keep digital government alive under kinetic assault. Their flagship platform, Diia, had to remain operational through missile strikes, cyberattacks, and no-connectivity zones. They turned to hardened patterns born in commercial and defense sectors—reliable automation, version-controlled infrastructure, and independent validation.
Diia’s deployment model mirrored containerized mobile worker architectures developed for credentialing systems. Each instance can relocate geographically and reinitialize autonomously, running secure services with or without central command.
That autonomy was key. The Diia system didn’t just survive—it redeployed. Services were relocated, revalidated, and resecured at the edge, often without human intervention. Its resilience was no accident—it was the logical result of zero-trust operations at the edge, built around runtime cryptographic trust, not perimeter firewalls.
“We’re trying to make those capabilities not only quicker to get, but also put them into a form that development teams will integrate into their flow.”
This principle—capabilities integrated into the developer flow—is what transforms secure theory into secure operations.
Resilience Mechanisms
Resilience isn’t just an ideal—it’s a deliverable. The framework supports a repeatable bootstrapping mechanism that initiates operation without central authority. Air-gapped, disconnected, degraded—it doesn’t matter. The runtime stands itself up and guards its own perimeter.
No click-ops. No mission delay. Just a CLI for combat conditions.
This implementation reflects modernized DevSecOps policies pioneered by Air Force programs like Platform One and BESPIN, which proved that mobile-first deployments, governed by Continuous Authority to Operate (cATO), could be fielded quickly and scaled horizontally across classified and unclassified environments.
Core principles:
- Runtime identity = security posture. If it can't prove it’s safe, it doesn't run.
- Trust nothing. Verify everything. Network location means nothing—only verifiable identity counts.
- Logs are contracts. Every action is traced, hashed, and stored, even when disconnected.
- Team boundaries align with system boundaries. As Skelton and Pais (2019) identified in Team Topologies, "if team boundaries don't align with software boundaries, you get coupling and delays." This implementation ensures that operational responsibilities mirror technical architecture.
Analysis of production deployment data from mature product teams demonstrates this methodology's effectiveness with quantifiable metrics specific to mission-critical applications:
- Deployment automation ratio: 41.57% - Nearly half of all deployments occur without human intervention
- Average deployment time: 1.59 minutes - Rapid deployment enables quick response to changing conditions
- Security issue prevalence: 1.37% - Minimal security vulnerabilities due to structural validation
These metrics represent performance in production environments for teams in the optimization phase of their product lifecycle, not aggregated multi-environment averages across different maturity levels.
This is how a container becomes a hardened asset. A drone in software form—machinery that moves through digital terrain under pressure, under fire, under silence.
Disconnected survivability requires autonomous state validation. Edge systems, ruggedized devices, and classified environments cannot assume DNS availability or centralized orchestration. For these deployments, survivability means the ability to wake from power loss, validate environment state locally, rotate secrets from cache or store, and resume execution without human intervention. These systems must behave as autonomous actors with immutable behavioral contracts. This machinery demands that every node operate as its own operational authority—structured to refresh credentials automatically, detect configuration anomalies, and regenerate operations during environmental chaos.
Applying battlefield-proven military principles, the worker implementation (hosted on GitHub, though similar repositories could be maintained on Bitbucket, GitLab, or other version control platforms) demonstrates how zero trust functions in operational reality:
Authentication and Runtime Are One Continuum: A container that can't validate its security posture doesn't run—period. There's no degraded security mode or warning-only option.
Security Is Protocol, Not Afterthought: Workers validate their entire environment before executing application code, ensuring security is built into the process from the beginning.
Access Based on Verifiable Identity: Service components don't trust based on network location—they verify cryptographic identities for every interaction, mirroring how military communications authenticate on shared frequencies.
This model has proven critical in environments from university physical access control systems to financial transaction processing for government institutions. The approach ensures systems remain secure even when operators can't physically access infrastructure—a requirement that emerged from work with educational institutions managing distributed campus security with limited IT staff.
Deployment Configuration
The worker configuration for field deployment focuses specifically on resilience and local validation in disconnected environments:
kind: workerConfig
version: v1
config:
env:
SITE_URL: "https://${CI_BRANCH_NAME}.preview.udx.io"
WP_DEBUG: "true"
WP_DEBUG_LOG: "true"
WP_DEBUG_DISPLAY: ${WP_DEBUG_DISPLAY}
WP_ENVIRONMENT_TYPE: "${WP_ENVIRONMENT_TYPE}"
WP_CRON_DISABLED: "true"
DB_NAME: "${CI_LIFECYCLE_NAME}"
DB_USER: "core"
secrets:
DB_PASSWORD: "gcp/secrets/wordpress-database-password"
GOOGLE_API_KEY: "gcp/secrets/google-maps-api-key"
AUTH_KEY: "gcp/secrets/wordpress-auth-key"
URI-based secret references abstract away cloud-specifics. For WordPress implementations, these environment variables and secrets eliminate the need for hardcoded database credentials and configuration constants in wp-config.php, allowing the same container to run securely across environments while automatically detecting its context. The framework is entirely content-agnostic - it doesn't matter if you're running WordPress, a custom application, or a specialized military service. What matters is the declaration pattern, not what's inside the box. The result? A worker that starts, validates, and runs the same way anywhere - public cloud, disconnected bunker, or temporary FOB.
This structure allows zero-downtime credential rotation, provider-neutral deployments, and code-integrated compliance—key elements mirrored in modular Air Force frameworks including DoD Enterprise DevSecOps Strategy Guide, BESPIN’s MDaaS and Platform One’s DevSecOps PaaS.
By shifting validation left and embedding it into startup logic, survivability becomes systemic. The config is the contract, and that contract is enforced by the runtime. Every node, every time.
Mission-Critical Assets
Here’s the bottom line: the same logic that governs resilient deployments at the edge also governs unmanned systems in flight. Each drone is a node. Each microservice, a mission component. Both must start independently, prove their identity, validate their operating conditions, and perform—even when alone.
That’s what this approach delivers: not just automation, but autonomy. And autonomy is what survives.
Transparency at Scale
When implemented at national scale, this approach delivers enterprise-class transparency and auditability - mission-critical capabilities that transform infrastructure from a vulnerability to a strategic asset. These capabilities become foundational for organizations operating critical systems where trust is non-negotiable.
At this tier, governance isn't a separate layer - it's structurally embedded in every deployment. The system doesn't recommend compliance - it enforces it through cryptographically verified audit trails and automated validation gates that operate with mathematical precision.
Most critically, this architecture scales linearly with zero governance overhead. The same patterns that secure 10 deployments secure 10,000 without additional committees, approval boards, or operational bottlenecks - a capability previously unavailable at enterprise scale.
A key component of this structural enforcement is SBOM-centric workflows that enable auditable integrity across the full delivery chain. A software bill of materials (SBOM) embedded in the release workflow ensures that every deployed artifact carries its own declaration of components, licenses, cryptographic hashes, and dependency chains. These SBOMs are not passive documentation—they are required inputs for pipeline continuation. Systems that cannot produce complete, validated SBOMs are not allowed to progress. This makes component transparency a blocking constraint, not a compliance afterthought, and enables traceability to survive organizational and infrastructural change.
The system ultimately becomes its own evidence. Cryptographically signed artifacts, audit trails, commit hashes, and validated secrets resolution paths ensure that systems are not only operational but provable. Evidence of readiness, compliance, and security is generated by the system itself, in the course of execution. No separate audit cycle is required. Observability and governance are baked into the infrastructure, not imposed after the fact. What is running is what was declared—and if it is not declared, it does not run.
This structural approach eliminates the most common failure modes in large-scale deployments:
- Missing secret? → Container halts automatically
- Drifted config? → Diff is auditable with precise tracking
- Security audit? → Every artifact carries cryptographic verification
- Need to redeploy? → Same artifact, same result across environments
The result is a system that doesn't rely on institutional memory or individual expertise. Like a well-designed military operation, the plan is encoded directly into the deployment infrastructure rather than depending on individual knowledge.

This CI/CD workflow (implemented here using GitHub Actions, though similar patterns work with Jenkins, GitLab CI, Azure DevOps, or other platforms) demonstrates the methodology in action—automating the entire process from commit to production with validation at every stage. Each checkpoint represents a control gate that enforces the principles established earlier: validating secrets, verifying configurations, and ensuring runtime integrity.
Immediate Auditability: Security officers don't need to trust the process—they can verify it directly. The system provides its own evidence of readiness through cryptographically verified data pipelines, creating a continuous chain of trust from development to production.
National Impact

The metrics from Transact's implementation across America's higher education market validate this architectural approach with remarkable results across multiple dimensions. As demonstrated in the Transact Apple Partnership video, this collaboration transformed campus access systems nationwide while maintaining rigorous security standards. Developer velocity increased by an impressive 700% through the implementation of automated validation gates, enabling teams to innovate faster without sacrificing quality. Simultaneously, release time compressed dramatically from 30 days to just 4 days via self-validating deployments that eliminated manual approval bottlenecks. Perhaps most significantly, the system maintained zero security incidents despite processing billions in transactions across major institutions—a testament to the effectiveness of structural controls over administrative oversight.
The operational transformation was equally profound, with deployment frequency surging from merely 5 per month to over 400 monthly deployments. This acceleration didn't come at the expense of security; in fact, automated validation reduced security incidents by 92% across the platform. The compliance landscape was similarly transformed, with audit scope compressed by 99.7% through cryptographic verification that eliminated manual sampling. Compliance validation time shrank from weeks to hours through automated checks, while maintaining rigorous adherence to SOC 2, PCI DSS Level 1, and ISO 27001 compliance with comprehensive security standards.
The cloud-first transformation helped Transact Campus evolve from a traditional software provider to a cloud-native enterprise. This transformation added approximately $1B to their valuation through the Transact IDX platform that now serves over 120 institutions with 8-second transaction processing, representing significant momentum in migrating customers from their on-premise TSOP platform (with approximately 700 installations) to their cloud-based solution. This implementation demonstrates how these principles translate into measurable business outcomes when applied at national scale.
The national impact extends beyond technical metrics—students across America now use their phones to access buildings, pay for meals, and manage their campus life using mobile credentials, with infrastructure that maintains continuity during regional outages and scales efficiently during peak periods like semester start. This includes NFC-based access that integrates with security readers globally, enabling fast dorm access via Apple/Google Wallets, with high adoption rates at leading universities.
This design enables application across industries. Rather than creating a point solution, the architecture provides a repeatable pattern that has been successfully implemented in educational, healthcare, financial, and defense sectors, proving its versatility across mission-critical domains.
This success exemplifies what Forsgren, Humble, and Kim (2018) identify in Accelerate as the impact of transformational leadership: "Leaders who empower and remove blockers drive success" in high-performing technology organizations. These principles set the foundation for future evolution of cloud hopping capabilities as we'll explore in the next section.
Access Authority
This approach to security and compliance represents a fundamental shift from traditional models. Rather than treating controls as administrative overhead, they become structural elements of the system itself—embedded in the architecture rather than imposed from outside.
This structural approach addresses one of the most challenging aspects of modern security: separating information access from system change authority. Traditional implementations of least privilege often fail because they conflate these two distinct needs:
- Access to information - The ability to view, analyze, and understand system components
- Authority to change - The ability to modify, deploy, or reconfigure those components
When these are treated as a single permission, organizations face a difficult choice: either grant excessive authority (creating security risks) or restrict information access (hampering innovation). This methodology resolves this dilemma by structurally separating these concerns.
Consider how this plays out in practice across the organization's key roles and responsibilities. Developers gain complete visibility into configurations, secrets resolution paths, and deployment patterns—yet cannot directly modify production environments, allowing them to understand the system without introducing risk. Operations teams can deploy validated artifacts with confidence but cannot modify their contents, maintaining the integrity of what was tested and approved. Security teams can verify compliance continuously without disrupting workflows, eliminating the traditional tension between security and productivity. Auditors benefit from the ability to trace every change through cryptographically verified chains, providing unprecedented transparency without manual investigation.
This separation is not achieved through permission matrices or role definitions—it's built into the deployment machinery itself. The system physically separates the concerns that traditional models try to separate logically.
Evidence Collection
A critical but often overlooked aspect of compliance is evidence collection—the ability to demonstrate that controls are not just defined but actually working. Traditional approaches treat evidence as an afterthought, requiring manual collection during audit periods that disrupts normal operations and creates significant overhead and toil.
This methodology transforms evidence collection from a periodic audit activity into a continuous, automated process embedded throughout the software development lifecycle. During the design phase, architecture decisions are captured with cryptographic signatures that link requirements to implementation choices, creating traceable connections between business needs and technical solutions. In the development phase, every code change is automatically validated against security policies before entering the pipeline, ensuring compliance from the earliest stages of creation. As code moves through the testing phase, security validation results are preserved as immutable records that travel with the code, maintaining a continuous chain of evidence. The deployment phase extends this validation through runtime checks that generate their own evidence of proper execution, while the operations phase completes the cycle with continuous monitoring that creates verifiable audit trails of system behavior.
This approach generates what auditors call "evidence of effectiveness"—proof that controls are not just documented but functioning as intended. The evidence produced by this methodology is comprehensive, covering the entire SDLC rather than isolated checkpoints, which eliminates blind spots in compliance verification. It's also continuous, generated as a natural byproduct of operations rather than as a separate activity that disrupts normal workflows. Perhaps most importantly, this evidence is cryptographically verifiable—tamper-evident and mathematically provable—creating an immutable record that satisfies even the most stringent audit requirements. The contextual richness of this evidence, containing the who, what, when, where, and why of each action, provides unprecedented transparency into system operations without requiring manual investigation or documentation.
When an auditor asks, "How do you ensure separation of duties?" the answer isn't a policy document—it's a cryptographically verified chain of evidence showing exactly how each deployment was validated, by whom, and under what conditions. This represents a paradigm shift from documentation-based compliance to evidence-based validation that transforms how organizations approach governance.
Compliance Design
Modern compliance frameworks increasingly recognize this structural approach as superior to traditional controls. While they use different terminology, the core principles align with this architectural approach:
PCI DSS v4.0.1 emphasizes "security by design" principles that embed controls into systems rather than adding them afterward. Requirement 6.4.3 specifically addresses separation of duties between development and production environments, while Requirement 7.2.4 mandates the implementation of least privilege access control systems. The March 2022 release of PCI DSS v4.0 introduced the concept of "customized implementation" that allows organizations to implement alternative controls that meet security objectives—precisely the approach this methodology enables.
NIST SP 800-53 Rev. 5 defines access control (AC) requirements that separate information flow from execution authority. Control AC-5 explicitly addresses separation of duties, requiring that organizations "separate [assignment: organization-defined duties of individuals]" and "implement separation of duties through assigned information system access authorizations." Additionally, the SA-8 control family emphasizes "security engineering principles" that align perfectly with this structural approach to security.
CMMC 2.0 builds on NIST frameworks to create defense-specific implementations, with practices like AC.L2-3.1.5 requiring the employment of least privilege principles, including "for specific security functions and privileged accounts." This architectural approach naturally satisfies these requirements through its structural design rather than through administrative controls.
This implementation satisfies these requirements not through administrative controls but through structural enforcement. When a container validates its own secrets, verifies its configuration, and cryptographically signs its audit trail, compliance becomes an inherent property of the system rather than a separate activity.
Continuous Validation
Traditional compliance models operate on a point-in-time basis—systems are certified compliant during an assessment, but may drift from that state immediately afterward. This creates a fundamental disconnect between compliance status and actual security posture.
This approach eliminates this gap through continuous validation mechanisms that enforce compliance as an ongoing condition of operation:
- Runtime Configuration Validation: Each container validates its configuration against security requirements before execution
- Secrets Resolution Verification: Credential access is cryptographically verified against authorization policies in real-time
- Deployment Pipeline Enforcement: Security gates validate every change against compliance requirements before promotion
- Immutable Audit Trails: Every system interaction generates tamper-evident records that persist independently of the systems themselves
This continuous approach transforms compliance from a periodic assessment into a persistent state. Systems don't just pass audits—they structurally cannot operate in non-compliant states. The architecture itself becomes the enforcement mechanism.
Critical Controls
Compliance professionals recognize specific controls that are particularly challenging to implement effectively. This architectural approach inherently addresses seven of these critical controls without requiring additional overhead:
Runtime Software Integrity (NIST SI-7): This methodology implements continuous runtime verification that prevents unauthorized code execution. Each container validates its integrity before and during execution, satisfying NIST SP 800-53 SI-7 requirements for "software, firmware, and information integrity." This control is particularly critical for financial systems where runtime tampering could enable fraud.
Secure Configuration Management (NIST CM-6, PCI DSS 2.2): Configuration validation is structurally enforced at runtime rather than periodically checked. This satisfies NIST CM-6 requirements for "configuration settings" and PCI DSS 2.2 requirements to "develop configuration standards for all system components." This approach ensures configurations cannot drift from their secure baseline during operation.
Least Functionality (NIST CM-7, CMMC AC.L2-3.1.2): Containers run with precisely the capabilities they need—nothing more. This implements NIST CM-7 requirements to "restrict component functions, ports, protocols, and services" and CMMC AC.L2-3.1.2 requirements to "limit information system access to the types of transactions and functions that authorized users are permitted to execute." The architecture physically prevents capability expansion without explicit declaration.
Cryptographic Key Establishment and Management (NIST SC-12, PCI DSS 3.6): The secrets resolution system implements NIST SC-12 requirements for "cryptographic key establishment and management" and PCI DSS 3.6 requirements to "fully document and implement all key-management processes and procedures." Keys are automatically rotated, validated, and protected throughout their lifecycle without manual intervention.
Information Flow Enforcement (NIST AC-4, CMMC AC.L2-3.1.3): The architecture enforces information flow policies at the container level, satisfying NIST AC-4 requirements to "enforce approved authorizations for controlling the flow of information within the system and between connected systems." This control is particularly important for multi-tenant systems where data segregation is critical.
Continuous Monitoring (NIST CA-7, PCI DSS 11.5): This methodology implements NIST CA-7 requirements for "continuous monitoring" and PCI DSS 11.5 requirements to "deploy a change-detection mechanism to alert personnel to unauthorized modification." Unlike traditional implementations that check periodically, this monitoring is structurally embedded in the runtime environment itself.
Audit Record Generation (NIST AU-12, CMMC AU.L2-3.3.1): Every system interaction automatically generates cryptographically verifiable audit records, satisfying NIST AU-12 requirements to "generate audit records for events" and CMMC AU.L2-3.3.1 requirements to "create and retain system audit logs and records." This implementation ensures these records cannot be tampered with or bypassed.
These controls are not implemented as separate compliance features—they are inherent properties of the architecture itself. A system built on this methodology doesn't need separate tools or processes to satisfy these requirements; they are structurally enforced by the deployment machinery. This creates a self-validating infrastructure that maintains compliance as an operational state rather than a periodic achievement.
SDLC Controls
The most powerful compliance advantage comes from implementing controls at the software logistics level—the entire SDLC pipeline from code commit to production deployment. This approach fundamentally transforms how compliance is achieved:
Complete Change Reversibility: Every change in the system is reversible by design. This methodology implements NIST SP 800-53 CM-3 (Configuration Change Control) and CM-5 (Access Restrictions for Change) not through administrative approvals but through structural enforcement. Changes are tracked cryptographically from commit to deployment, creating an immutable record that enables precise rollback when needed. This satisfies PCI DSS v4.0.1 requirement 6.4.1 to "manage all changes to system components" while eliminating the traditional overhead of change control boards.
End-to-End Visibility: This methodology provides complete visibility across the entire pipeline without granting modification rights. This implements NIST AC-6 (Least Privilege) in a way that separates information access from change authority. Developers, operations teams, and security personnel can see everything happening in the system without being able to bypass controls—satisfying CMMC AC.L2-3.1.5 requirements for separation of duties while enabling innovation through information sharing.
Structural Enforcement of Controls: Rather than relying on policy documents or manual reviews, this methodology enforces controls through the deployment machinery itself. This implements NIST SA-10 (Developer Configuration Management) and SA-11 (Developer Security Testing and Evaluation) as structural components of the system. The pipeline physically prevents non-compliant changes from progressing, satisfying OWASP ASVS requirement V1.1.2 to "use a secure software development lifecycle" without creating process overhead.
Automated Evidence Generation: Every step in the pipeline generates its own evidence of compliance. This implements NIST AU-2 (Audit Events) and AU-3 (Content of Audit Records) as a natural byproduct of normal operations. The system doesn't just log activities—it cryptographically verifies them, creating tamper-evident records that satisfy PCI DSS v4.0.1 requirement 10.2.1 to "implement audit trails" without requiring separate audit tools.
This approach transforms compliance from a documentation exercise into an operational reality. The system doesn't just document controls—it enforces them through its very architecture. This is why organizations implementing this methodology report dramatic reductions in compliance overhead: the same mechanisms that make the system operationally resilient also make it inherently compliant.
Framework Alignment
This architectural approach extends beyond traditional compliance frameworks to address modern development methodologies and security standards. This comprehensive alignment creates a unified approach that satisfies requirements across multiple domains:
OWASP Application Security Verification Standard (ASVS) requirements are structurally enforced through this architectural approach. For example, OWASP ASVS v4.0 requirement V1.14 (Verify that a secure software development lifecycle is in place) is satisfied through automated validation gates and cryptographic verification. The architecture specifically addresses OWASP Top 10 risks like A2:2021 (Cryptographic Failures) through its secrets resolution system and A5:2021 (Security Misconfiguration) through its runtime configuration validation.
Twelve-Factor App methodology principles are embedded in this architectural design, particularly Factor III (Config - store configuration in the environment) and Factor XI (Logs - treat logs as event streams). The approach to configuration management and logging aligns perfectly with these principles, ensuring that applications built on this architecture inherently follow cloud-native best practices. This alignment is particularly important for organizations adopting modern cloud platforms while maintaining compliance with traditional regulatory frameworks.
DevSecOps Integration occurs naturally through structural controls. Security gates in the CI/CD pipeline implement NIST SP 800-218 (Secure Software Development Framework) practices like PO.1.1 (Define security requirements for software development) and PO.3.2 (Implement and maintain secure configurations for build tools). These controls are not bolted-on security checks but integral components of the development workflow.
Zero Trust Architecture principles from NIST SP 800-207 are implemented through this approach to authentication and authorization. The architecture enforces the core Zero Trust principle that "no network is implicitly trusted" by requiring continuous validation of every component's identity and authorization before allowing access to resources.
For regulated industries facing complex compliance requirements across multiple frameworks (PCI DSS, HIPAA, SOC 2, FedRAMP, etc.), this architectural approach dramatically reduces the overhead of maintaining compliance. Rather than implementing separate controls for each framework, organizations implement a single architectural pattern that satisfies the underlying security objectives of all frameworks simultaneously.
This approach transforms how organizations think about least privilege. Instead of asking "What's the minimum access needed to perform a function?" the question becomes "How do we structure systems so access and authority are naturally separated?" The result is both more secure and more conducive to innovation—teams can see everything they need without being able to change what they shouldn't.
Real-World Impact
These principles have been validated not only in commercial deployments but in actual conflict zones. The Ukraine deployment mentioned earlier represents the most demanding test case. Under active wartime conditions, the approach enabled critical infrastructure to maintain operations while moving faster than threats could evolve—demonstrating cloud hopping as both a technical architecture and a defensive strategy.
This evolution in security posture proves that digital resilience doesn't require continuous upstream access or human intervention. The same deployment patterns work consistently whether running on public cloud infrastructure or ruggedized edge devices in contested environments where connectivity is intermittent at best.
What is observed in these implementations is the methodology's military origins coming full circle. Concepts that began as operational doctrine transferred to civilian use have now demonstrated their value in genuine conflict scenarios. This convergence of military discipline with modern software engineering creates a new paradigm where software deployment becomes not just an operational concern but a strategic capability—in essence, software as a warfighting domain.
The implications extend beyond current capabilities. This approach fundamentally reimagines how digital operations will function in the contested environments of 2030 and beyond, where the distinction between civilian and military digital infrastructure will continue to blur. The next chapter explores how these proven principles will evolve to address emerging threats and opportunities in the cloud hopping future.
Structural Enforcement
The principles established throughout this document—Crypto Canary, Repository-Centric Architecture, and Self-Validating Deployments—converge to create a transformative capability: the ability to deploy software with absolute confidence regardless of environmental conditions. This final chapter examines how these principles translate into practical implementation, economic advantages, and strategic capabilities that fundamentally change how organizations approach deployment operations.

The visualization above represents the complete lifecycle of deployment machinery—from code commit to production operation. Each gate functions as an executable checkpoint that enforces validation automatically rather than relying on human oversight. This machinery doesn't just automate existing processes; it fundamentally transforms them by embedding validation as a structural property rather than an applied procedure.
Strategic Advantage
Most organizations operate with a significant capability gap between their deployment aspirations and operational reality. The timeline below illustrates this gap, with the left side representing conventional approaches and the right showing what Cloud Hopping delivers:

This evolution isn't merely theoretical—it represents practical capabilities that organizations can implement today:
Application lifecycles measured in hours instead of weeks: Structural validation enables rapid iteration without sacrificing quality or security.
Security validation integrated into deployment: Security becomes an inherent property of the deployment process rather than a separate concern.
Stateless architectures enabling true cloud hopping: Applications can move seamlessly between environments without reconfiguration.
Infrastructure that adapts to threats: Systems detect degradation and relocate automatically without human intervention.
Containerized deployments with hybrid infrastructure support: Workloads operate consistently across any cloud provider or on-premises environment.
The economic impact of these capabilities is profound. Organizations implementing these principles have achieved 10-20x higher deployment frequencies while reducing incidents by 80-90%. This isn't a tradeoff between speed and safety—it's a fundamental realignment where the most secure deployment is also the most efficient.
Structural Solutions to Container Security Challenges
At the foundation of Cloud Hopping is a robust infrastructure built on containerization principles. The chart below identifies the critical security challenges that must be addressed:

The visualization reveals that the most critical security challenges cluster around the container ecosystem itself. Organizations build on open source images they neither created nor can fully inspect, yet these components form the bedrock of their infrastructure. The Worker platform directly confronts these challenges through structural enforcement:
Shifting Security Left: The Worker Supply Chain
The Worker container image implements the principles established throughout this document, creating a foundation for secure, portable deployments. The following progression shows how Worker components shift security left in the supply chain:
This progression demonstrates how security shifts left in the development lifecycle, becoming an inherent property of the system rather than a bolt-on addition. Each component builds upon the previous one, creating a comprehensive security model that addresses the challenges identified in the container security chart.
Wright's Law: The Economics of Structural Enforcement
The Cloud Hopping architecture fundamentally transforms the economics of security operations through the application of Wright's Law—the empirical observation that unit costs decline predictably as production volumes increase. This principle is expressed mathematically as:
Where:
- (C(X)) = Cost of the (X)th deployment
- (C_1) = Cost of the first deployment
- (X) = Cumulative volume of deployments
- (p) = Learning rate
Analysis of Cloud Hopping implementations across 11,588 deployments reveals a learning rate of approximately 98.62%, meaning costs decrease by 1.38% each time deployment volume doubles. This cost reduction translates to measurable efficiency gains—the initial deployment cost of 10.15 hours at $55/hr ($558.25) provides a baseline for organizations to measure implementation efficiency as teams gain experience with the methodology.
Traditional security models treat protection as a cost center with diminishing returns, creating an inevitable tradeoff between security and functionality. The Cloud Hopping architecture systematically inverts this relationship by embedding validation as a structural property rather than an applied procedure. When security properties are enforced through structure rather than ceremony, security becomes an accelerant rather than a constraint.
Practical Implementation: Start Where You Are
The implementation approach for Cloud Hopping is refreshingly straightforward: start with Worker and build tooling that runs in a container, then apply the same principles to your own code. Use YAML manifests to declaratively define your environment and organize everything in repositories. This pattern has been tested in numerous enterprises, consistently transforming them into top performers. The method is repeatable, professionally auditable, and provides the baseline components needed to organize and secure your infrastructure.
This approach serves a broad audience of software professionals, IT management, and technology leadership. By implementing these principles, organizations gain access to hard metrics and concrete ratios to measure themselves against industry benchmarks. These metrics provide specific targets for self-assessment that enable organizations to pass any audit with confidence. Once multiple software logistics systems are coordinated, you will have a decentralized command and control center that allows you to leverage any cloud, refine code, and empower teams with both code and doctrine.
While sharing elements with traditional CI/CD approaches, this methodology fundamentally expands them by integrating compliance and controls directly into the pipeline. It creates software factories that bootstrap best practices and architects logistics for software refinement through rapid iteration. Its cloud-agnostic architecture facilitates compliant value delivery at velocity—making CI/CD both real and compliant.
Beyond 2025: Emerging Capabilities
As digital environments become increasingly contested, the principles established in this document are evolving into more sophisticated capabilities. Current trends reshaping deployment machinery include:
AI-Augmented Validation: Generative AI is transforming deployment validation through autonomous code analysis, predictive failure detection, and self-healing infrastructure. This machinery doesn't just detect issues—it anticipates and resolves them before they manifest.
Zero-Trust Mesh Networks: Digital trust frameworks are evolving beyond perimeter defense to continuous validation of every component's integrity. These systems enforce structural boundaries through cryptographic verification rather than policy documents.
Edge-Native Autonomy: Cloud and edge computing convergence enables deployment units to operate with complete autonomy at the network edge, validating their state and rotating credentials without central coordination.
Quantum-Resistant Cryptography: As quantum computing advances, deployment machinery is incorporating post-quantum cryptographic algorithms that maintain security even against quantum attacks.
Predictive Infrastructure Defense: AI-enhanced systems now anticipate threats and initiate cloud hopping preemptively, moving workloads across providers before attacks materialize.
These capabilities represent the natural evolution of the principles established throughout this document, extending them to address increasingly sophisticated threats across public and private sectors.
The Machinery of Resilience
The Worker platform embodies what Womack, Jones, and Roos demonstrated in their study of lean manufacturing systems: when quality checks are built into every step, when flexibility is engineered into the architecture, and when speed comes from elimination of waste rather than cutting corners, systems consistently "outperform traditional approaches while using fewer resources."
At its core, Worker provides a base container image that implements these principles—from Crypto Canary to Self-Validating Deployments. It solves the critical vulnerability of secrets management while maintaining the clean separation of concerns necessary for secure, portable deployments. This isn't merely a tool for automation—it's a complete operational system that structurally enforces security, compliance, and resilience requirements through its runtime validation mechanisms.
The secure container environment provides the foundation for implementing robust security guardrails that encompass every component of the application stack:
- Secrets Management: NIST-compliant implementation of the Crypto Canary principle with support for multiple cloud providers
- Service Management: Orchestration capabilities for deploying and monitoring multiple services
- Configuration: YAML-based declarative configuration for environment variables and runtime parameters
- Authorization: Multi-provider credential management for seamless cloud integration
The machinery presented throughout this document represents more than a technical approach—it's an operational doctrine for digital resilience. From the Crypto Canary that validates mechanical integrity, to the Repository as Control Center that governs deployments, to Self-Validating mechanisms that enable survivability in contested environments—these principles create machinery that doesn't just survive disruption, it expects it.
The result is true digital resilience: the ability to deploy with impunity, regardless of conditions.
Appendix
This appendix consolidates all references, implementation resources, and technical knowledge that support the Cloud Hopping methodology. These resources provide deeper context and practical guidance for implementing the principles described throughout this document.
References
- Transact Apple Partnership Success Story - Demonstrates the successful implementation of mobile credentials in higher education
- Transact Mobile Credential Case Study - Shows how cloud hopping enables resilient operations at scale
- Microsoft Azure South Central US Outage Report - Detailed coverage of the September 2018 Azure outage referenced in the introduction
Literature
- Accelerate: The Science of Lean Software and DevOps - Forsgren, N., Humble, J., & Kim, G. (2018) - Empirical research establishing the connection between technical practices and organizational performance
- The DevOps Handbook - Kim, G., Humble, J., Debois, P., Willis, J., & Forsgren, N. (2021, 2nd ed.) - Practical guide to implementing DevOps principles with emphasis on flow, feedback, and continuous learning
- Team Topologies - Skelton, M. & Pais, M. (2019) - Organizational patterns that enable stream-aligned teams with clear boundaries and interfaces
- The Machine That Changed the World - Womack, J.P., Jones, D.T., & Roos, D. (1990) - Foundational study of lean manufacturing principles that inspired many software delivery practices
Standards
- NIST Guidelines for Securing Microservices - National Institute of Standards and Technology recommendations for securing microservices architectures
- DoD Enterprise DevSecOps Reference Design - Department of Defense guidelines for implementing secure DevOps in regulated environments
- Microsoft Digital Defense Report - Analysis of cybersecurity threats targeting critical infrastructure
- DORA State of DevOps Reports - Research-based insights on DevOps performance metrics and their impact on organizational outcomes
- CNCF Cloud Native Security - Cloud Native Computing Foundation's comprehensive guide to security in cloud-native environments
- Zero Trust Architecture - NIST SP 800-207 - Definitive framework for implementing zero-trust security principles
- Kubernetes Security Best Practices - Official guidance for securing Kubernetes deployments
Implementation
- 12-Factor Environment Automation - Comprehensive guide to implementing environment-based configuration management with runtime validation
- Why Software Logistics Matter - Foundational explanation of software logistics principles and their impact on operational resilience
- Operational Controls Implementation - Detailed patterns for implementing self-validating deployments with runtime integrity checks
- Cloud Automation Best Practices - Proven patterns for multi-cloud deployment with provider-agnostic implementation
- Operational Standards Framework - Standards for implementing repository-centric control with cryptographic verification
- Containerizing Legacy Systems - Practical approaches to implementing cloud hopping for existing applications
- Cloud Automation Introduction - Core concepts of cloud automation with emphasis on structural enforcement
- Collaborative Development Cadence - Team organization patterns that support high-velocity deployment
- Security in Platform-as-Code - Security implementation patterns for repository-centric architectures
Citations
- Google Cloud Secret Manager Quotas - Validates 10,000+ refs/region with 90,000 access requests per minute per project
- AWS Secrets Manager Quotas - Validates 5,000+ refs/region with 10,000 GetSecretValue API requests per second
- Azure Key Vault Service Limits - Validates 8,000+ refs/region with 4,000 transactions per 10 seconds for software keys
- Bitwarden Secrets Manager - Validates 2,000+ refs/org with Enterprise plan supporting unlimited secrets
- HashiCorp Vault Resource Quotas - Validates flexible scaling with configurable rate limits at multiple levels